SituationAdapt
Contextual UI Optimization in Mixed Reality with Situation Awareness via LLM Reasoning
ACM UIST 2024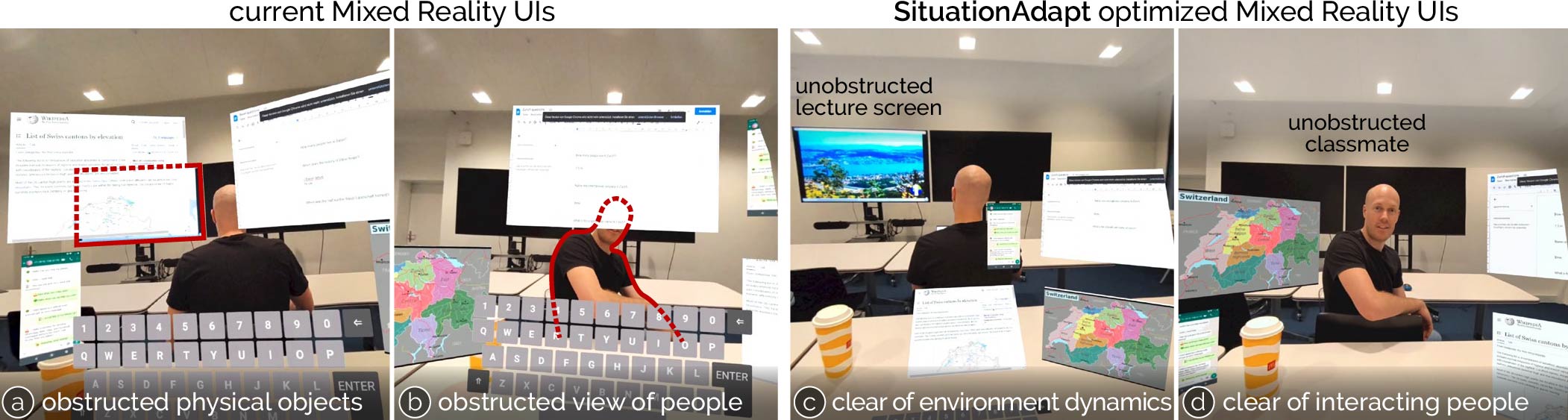
Abstract
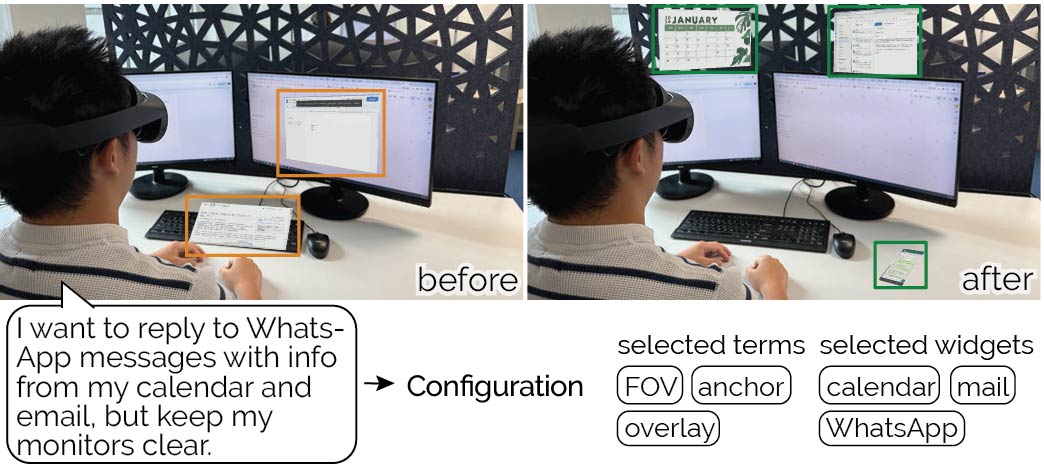
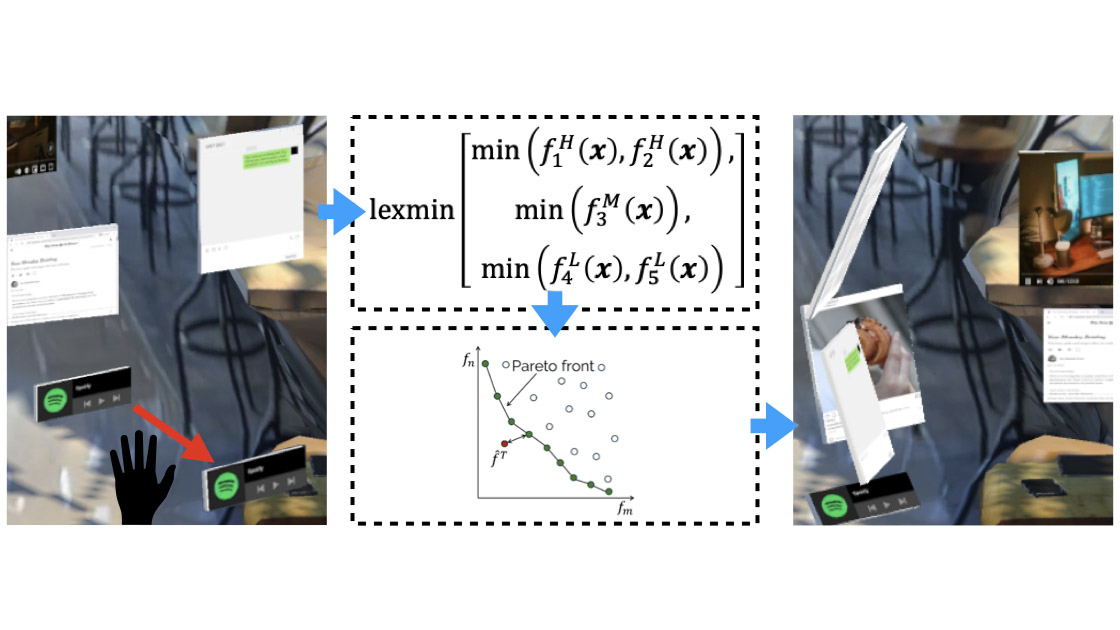
Mixed Reality is increasingly used in mobile settings beyond controlled home and office spaces. This mobility introduces the need for user interface layouts that adapt to varying contexts. However, existing adaptive systems are designed only for static environments. In this paper, we introduce SituationAdapt, a system that adjusts Mixed Reality UIs to real-world surroundings by considering environmental and social cues in shared settings. Our system consists of perception, reasoning, and optimization modules for UI adaptation. Our perception module identifies objects and individuals around the user, while our reasoning module leverages a Vision-and-Language Model to assess the placement of interactive UI elements. This ensures that adapted layouts do not obstruct relevant environmental cues or interfere with social norms. Our optimization module then generates Mixed Reality interfaces that account for these considerations as well as temporal constraints The evaluation of SituationAdapt is two-fold: We first validate our reasoning component’s capability in assessing UI contexts comparable to human expert users. In an online user study, we then established our system’s capability of producing context-aware MR layouts, where it outperformed adaptive methods from previous work. We further demonstrate the versatility and applicability of SituationAdapt with a set of application scenarios.
Video
Reference
Zhipeng Li, Christoph Gebhardt, Yves Inglin, Nicolas Steck, Paul Streli, and Christian Holz. SituationAdapt: Contextual UI Optimization in Mixed Reality with Situation Awareness via LLM Reasoning. In Proceedings of ACM UIST 2024.
Schematic overview
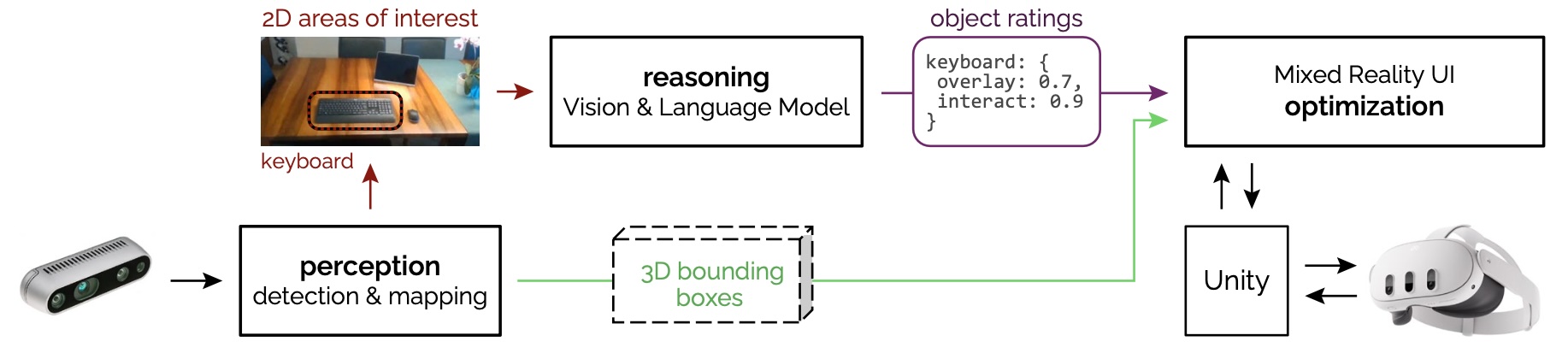
Figure 2: Schematic overview of SituationAdapt’s system. Our perception module recognizes 2D areas of interest in the environment and computes 3D bounding boxes of the respective objects. Our reasoning module takes the areas as input and leverages a VLM to rate their overlay- and interaction suitability. Unity then assigns these ratings to the respective 3D bounding boxes and our optimization module adapts MR UIs accordingly.
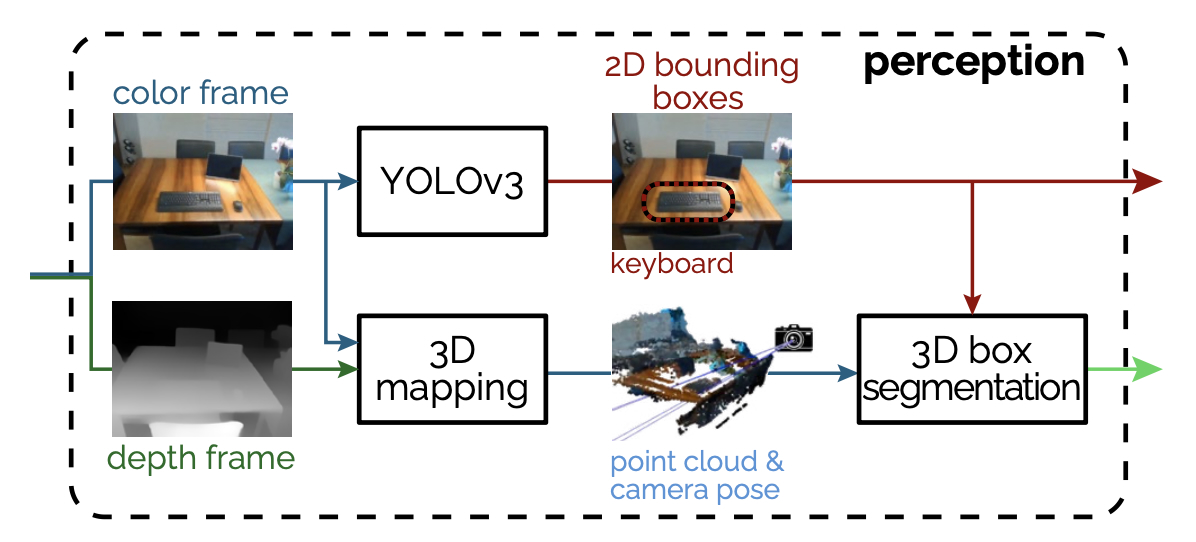
Figure 3: Our implementation of the perception module. Based on color- and depth frames of an RGBD camera, a 3D mapping stage reconstructs the camera position and the surroundings of the user as point cloud. An object detection node computes semantically annotated 2D bounding boxes. The last stage segments 3D bounding boxes based on the 2D ares, the point cloud and the camera position
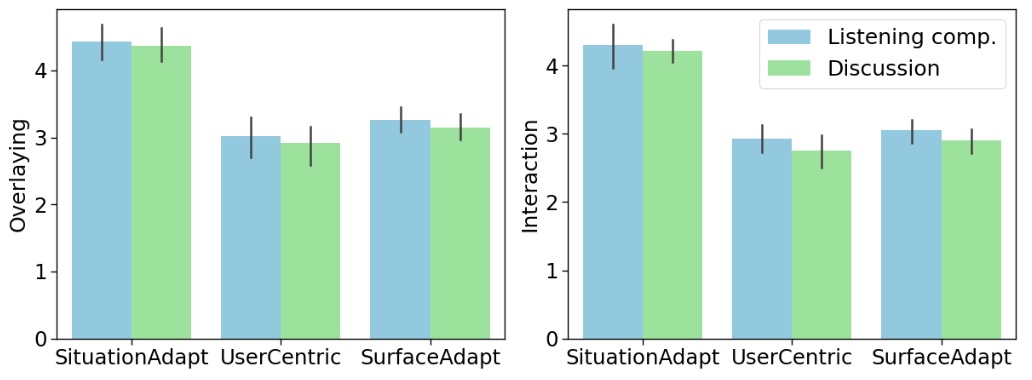
Figure 4: Mean and 95% confidence interval of participant ratings per condition for overlaying- (left) and interaction suitability (right) over all UI elements and tasks.

Figure 5: We demonstrate SituationAdapt’s versatility in six use-cases: (a) the user browses sports news while having food, (b) debug output of the perception module showing the point cloud and the detected bounding boxes for the colleague (blue) and the laptop (green), (c) the virtual interface is adapted to keep the colleague and laptop unobstructed, (d) the user puts the headset on finding virtual elements to occlude the plate and the warning sign, (e) debug output of the perception module illustrating the point cloud and the bounding boxes for the sink (purple), plate (green), and warning sign (glue), (f) the virtual elements are adapted to keep the plate, sink and warning sign unobstructed.