TapType
Ten-finger text entry on everyday surfaces via Bayesian inference
ACM CHI 2022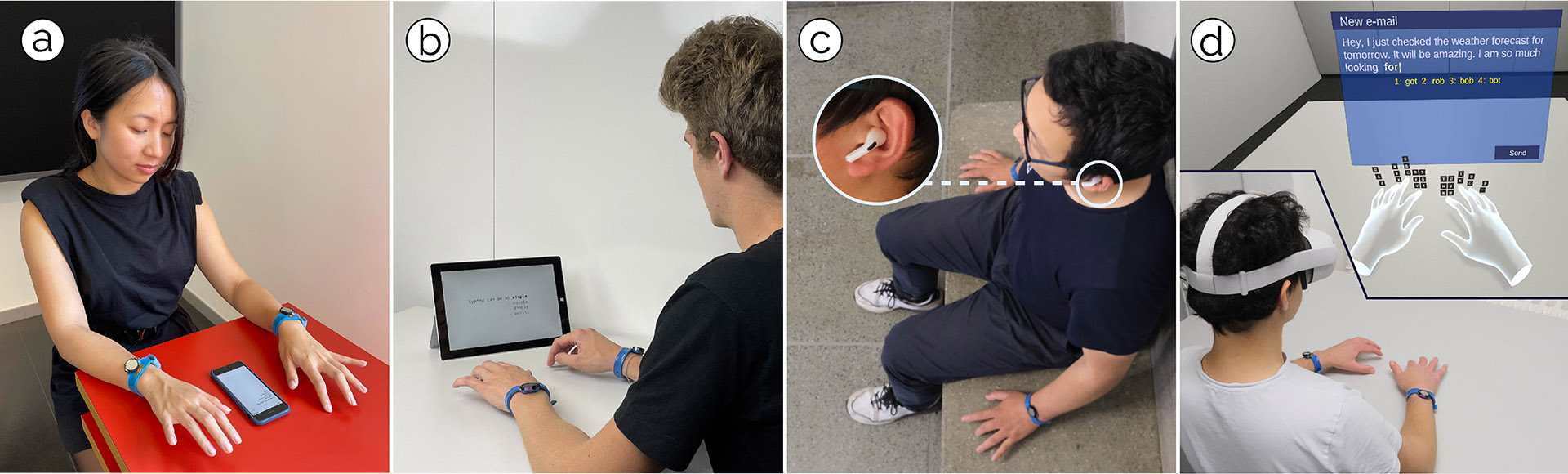
Abstract
Despite the advent of touchscreens, typing on physical keyboards remains most efficient for entering text, because users can leverage all fingers across a full-size keyboard for convenient typing. As users increasingly type on the go, text input on mobile and wearable devices has had to compromise on full-size typing. In this paper, we present TapType, a mobile text entry system for full-size typing on passive surfaces—without an actual keyboard. From the inertial sensors inside a band on either wrist, TapType decodes and relates surface taps to a traditional QWERTY keyboard layout. The key novelty of our method is to predict the most likely character sequences by fusing the finger probabilities from our Bayesian neural network classifier with the characters’ prior probabilities from an n-gram language model. In our online evaluation, participants on average typed 19 words per minute with a character error rate of 0.6% after 30 minutes of training. Expert typists thereby consistently achieved more than 25 WPM at a similar error rate. We demonstrate applications of TapType in mobile use around smartphones and tablets, as a complement to interaction in situated Mixed Reality outside visual control, and as an eyes-free mobile text input method using an audio feedback-only interface.
Video
Reference
Paul Streli, Jiaxi Jiang, Andreas Fender, Manuel Meier, Hugo Romat, and Christian Holz. TapType: Ten-finger text entry on everyday surfaces via Bayesian inference. In Proceedings of ACM CHI 2022.
More images
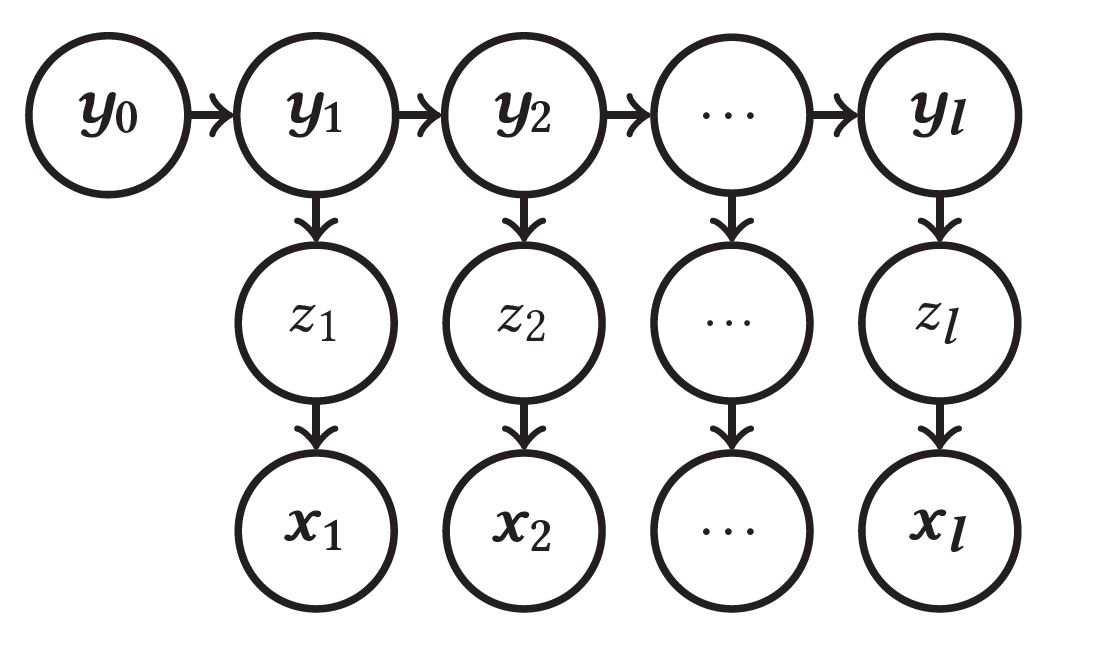
Figure 2: Hidden Markov model illustrating dependencies between a character yt typed at time step t and the corresponding finger tap zt that causes the observed vibration signals xt. The state of the system is described by the character sequence yt entered up and including to character yt.
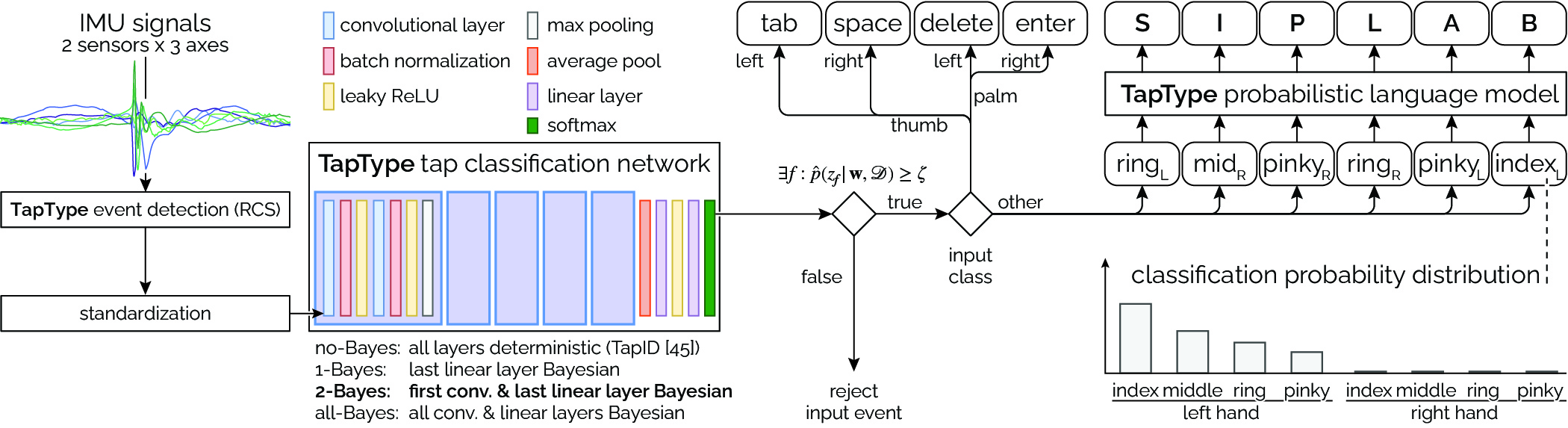
Figure 3: TapType’s processing pipeline consists of three parts: 1) a tap detection algorithm identifying sudden changes in the IMU signals, 2) a classification network that estimates the probabilities over the five fingers and the palm of the hand, and 3) a decoder that converts the classifier’s output sequence with priors from an n-gram language model to the most likely character sequence. We evaluated several architectures with varying placement of the Bayesian layers on their strength in providing effective probability distributions to the decoder and found 2-Bayes to produce to highest accuracy and robustness.
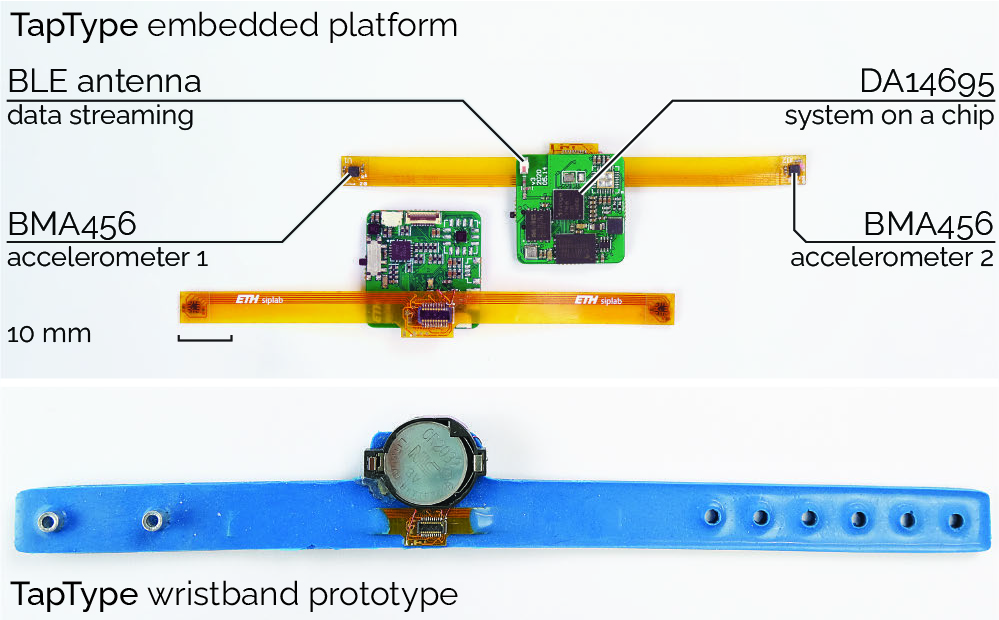
Figure 4: TapType’s wristband integrates two accelerometers and a mainboard in a silicone wrist strap (left). The battery-powered embedded platform (right) streams the signals via Bluetooth Low Energy to a computer for further processing.

Figure 5: For our data collection, several participants typed sentences on a QWERTY keyboard printed on an A3-sized paper. We logged finger tip motions using an OptiTrack alongside the IMU streams from both TapType wristbands. For ground-truth touch events and locations, we placed a capacitive touch sensor below the printed keyboard.

Figure 6: We compared our proposed Bayesian networks with our previous classifier as a baseline (TapID, labeled no-Bayes) on the F1 scores, ECE and NLL for cross-session (within-person), cross-person, and cross-person with 30-tap refinement evaluations. We evaluated three network designs: (a) 1-Bayes (replacing the last linear layer with a Bayesian linear layer), (b) 2-Bayes (replacing the first convolutional layer and last linear layer with Bayesian layers), (c) all-Bayes (replacing all convolutional and linear layers with Bayesian layers).
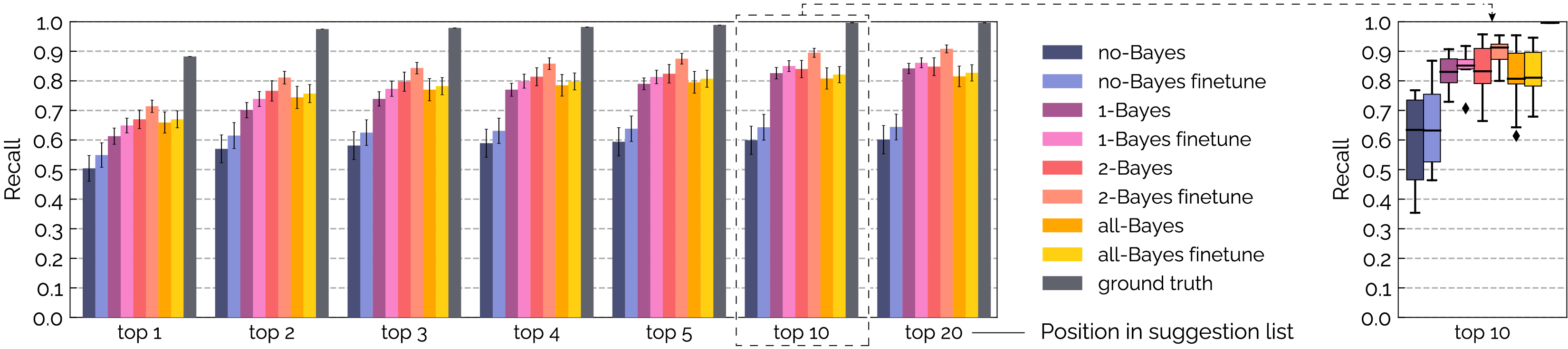
Figure 7: Simulation results of our text entry system by combining different finger classifiers. For each character, we randomly selected a sample of corresponding IMU signals from our dataset and fed them into the finger classifier. We then passed the predicted distribution of finger probabilities into our language model to generate a suggestion list. We counted the number of times the target word occurred in the top 1, 2, 3, 4, 5, 10, and 20 spots, and calculated the respective recall. The chart shows the average recall across participants. Error bars indicate the standard error across participants.
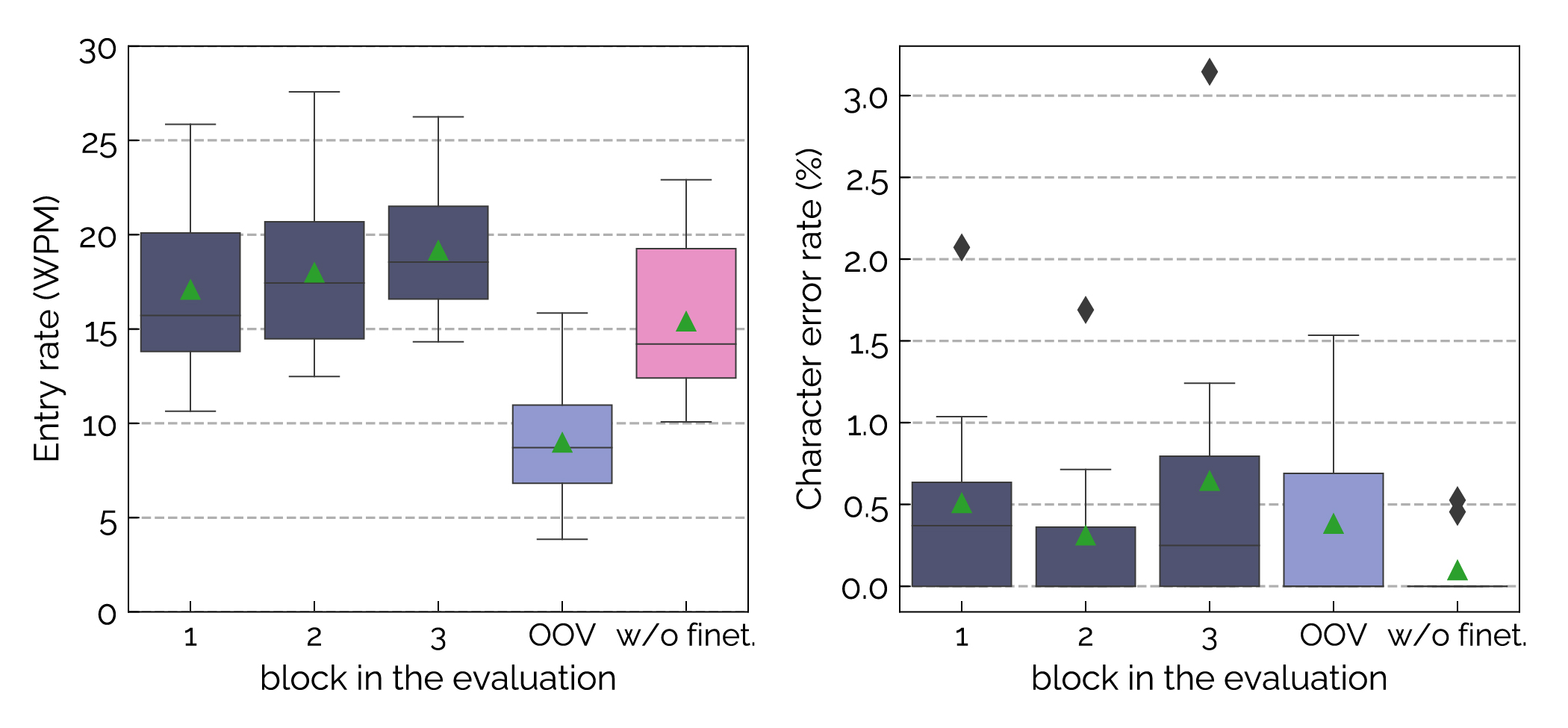
Figure 8: Results for our online text entry study with 10 participants. On average, participants entered text at a speed of at least 15 WPM during the first three blocks (1, 2, 3), reaching 19 WPM in the third block with a fine-tuned classifier. Text entry rates for phrases with OOV-words averaged 9 WPM. Without fine-tuning (w/o finet.), participants’ speed was around 15 WPM with a median CER of 0.0%.