TouchPose
Hand Pose Prediction, Depth Estimation, and Touch Classification from Capacitive Images
ACM UIST 2021
Abstract
Today’s touchscreen devices commonly detect the coordinates of user input using capacitive sensing. Yet, these coordinates are the mere 2D manifestations of the more complex 3D configuration of the whole hand—a sensation that touchscreen devices so far remain oblivious to. In this work, we introduce the problem of reconstructing a 3D hand skeleton from capacitive images, which encode the sparse observations captured by touch sensors. These low-resolution images represent intensity mappings that are proportional to the distance to the user’s fingers and hands. We present the first dataset of capacitive images with corresponding depth maps and 3D hand pose coordinates, comprising 65,374 aligned records from 10 participants. We introduce our supervised method TouchPose, which learns a 3D hand model and a corresponding depth map using a cross-modal trained embedding from capacitive images in our dataset. We quantitatively evaluate TouchPose’s accuracy in touch contact classification, depth estimation, and 3D joint reconstruction, showing that our model generalizes to hand poses it has never seen during training and that it can infer joints that lie outside the touch sensor’s volume. Enabled by TouchPose, we demonstrate a series of interactive apps and novel interactions on multitouch devices. These applications show TouchPose’s versatile capability to serve as a general-purpose model, operating independent of use-case, and establishing 3D hand pose as an integral part of the input dictionary for application designers and developers. We also release our dataset, code, and model to enable future work in this domain.
Video
Reference
Karan Ahuja, Paul Streli, and Christian Holz. TouchPose: Hand Pose Prediction, Depth Estimation, and Touch Classification from Capacitive Images. In Proceedings of ACM UIST 2021.
More images

Figure 1: TouchPose takes capacitive images from commodity touchscreen digitizers as input and recovers 3D hand poses. (A–F) Sample predictions by TouchPose on test images from our data corpus of aligned samples from a mutual-capacitance sensor, a depth camera, and a 3D hand pose estimator. TouchPose implements a multi-task scheme to simultaneously predict 3D hand poses and depth images. Red circles indicate actual contact points for illustration.
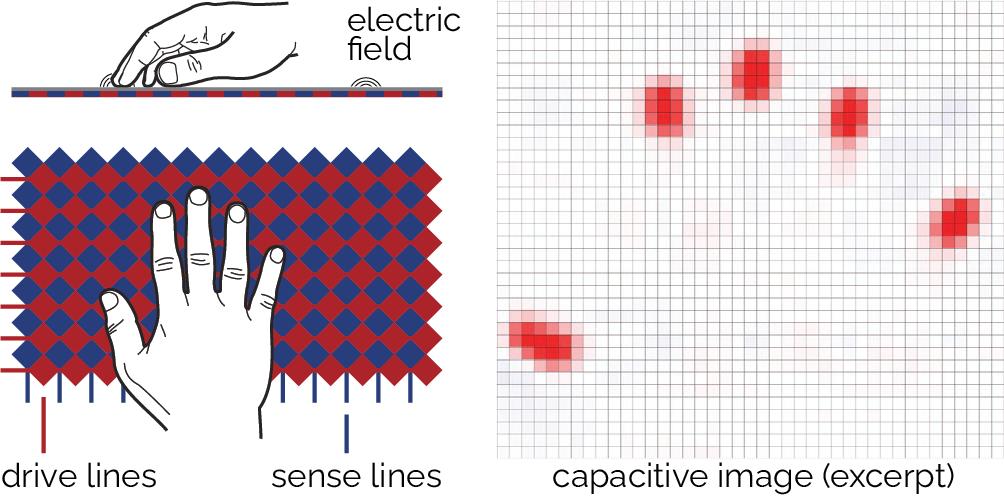
Figure 2: Typical diamond pattern of a mutual-capacitance touch sensor. Approaching fingers couple to the lines and cause a drop in capacitance between them. Right: Resulting capacitive image.

Figure 3: Data capture rig with mutual-capacitance touch panel, 16-bit touch digitizer, and cameras to record ground-truth data.
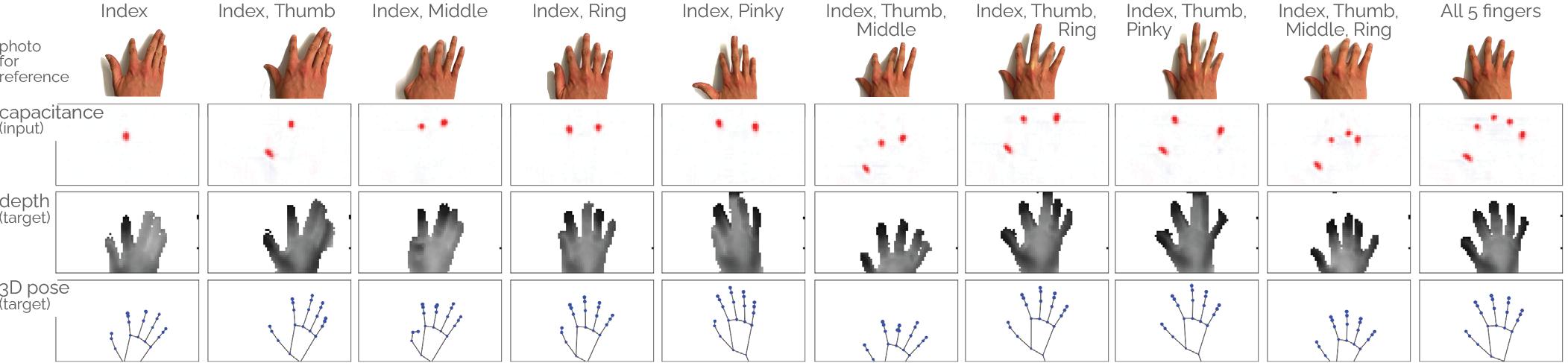
Figure 4: The 10 finger poses in our dataset. During each of the conditions (column), the labeled finger(s) were in contact with the surface. Note: The RGB pictures are for reference only and taken from above, while the depth images capture the hand from below. The 3D hand poses are visualized from the touch sensors perspective.

Figure 5: The 4 whole-hand poses in our dataset. Each column shows a condition. RGB pictures are for reference only.
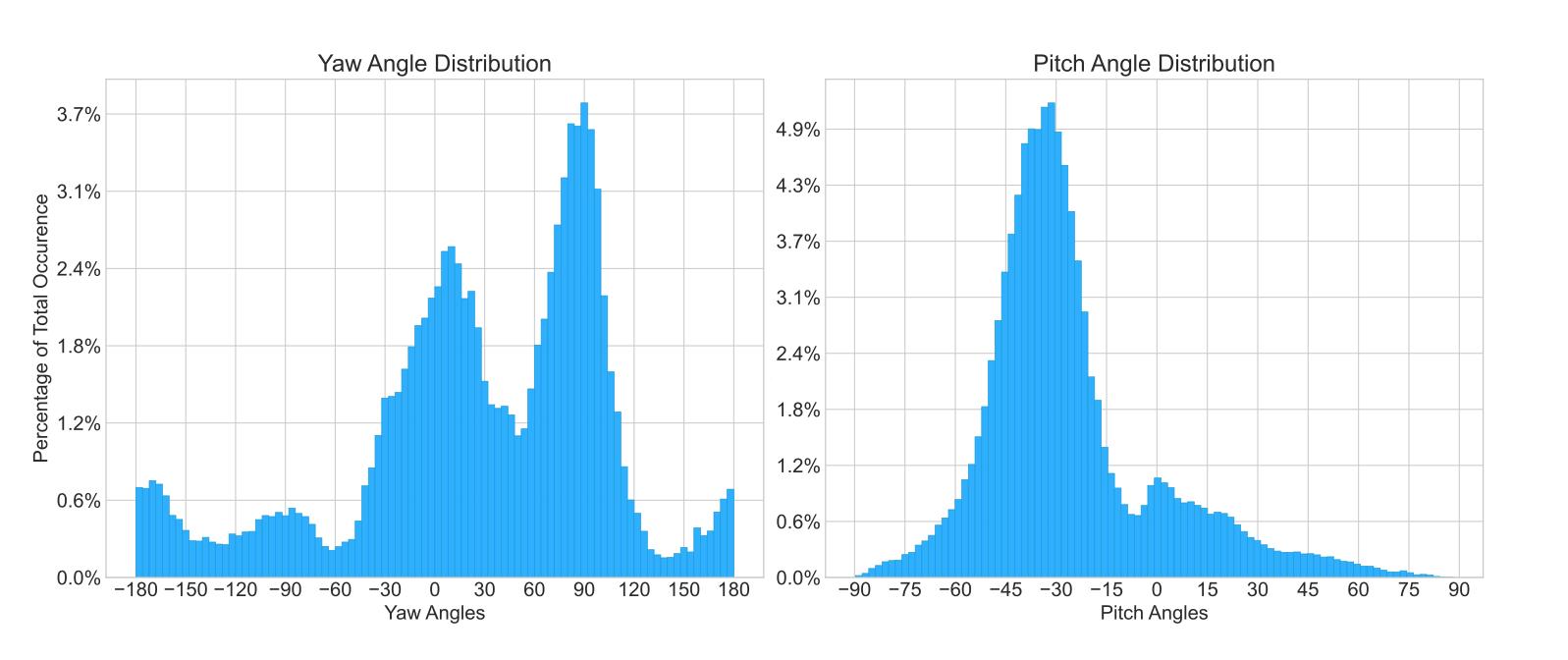
Figure 6: Dataset joint-angle distributions across all fingers for yaw (left) and pitch (right), respectively.

Figure 7: The same capacitive image (left) can result from different hand poses due to variations in orientation of fingers that are not touching the screen. Here, only index and middle fingers are touching the screen.
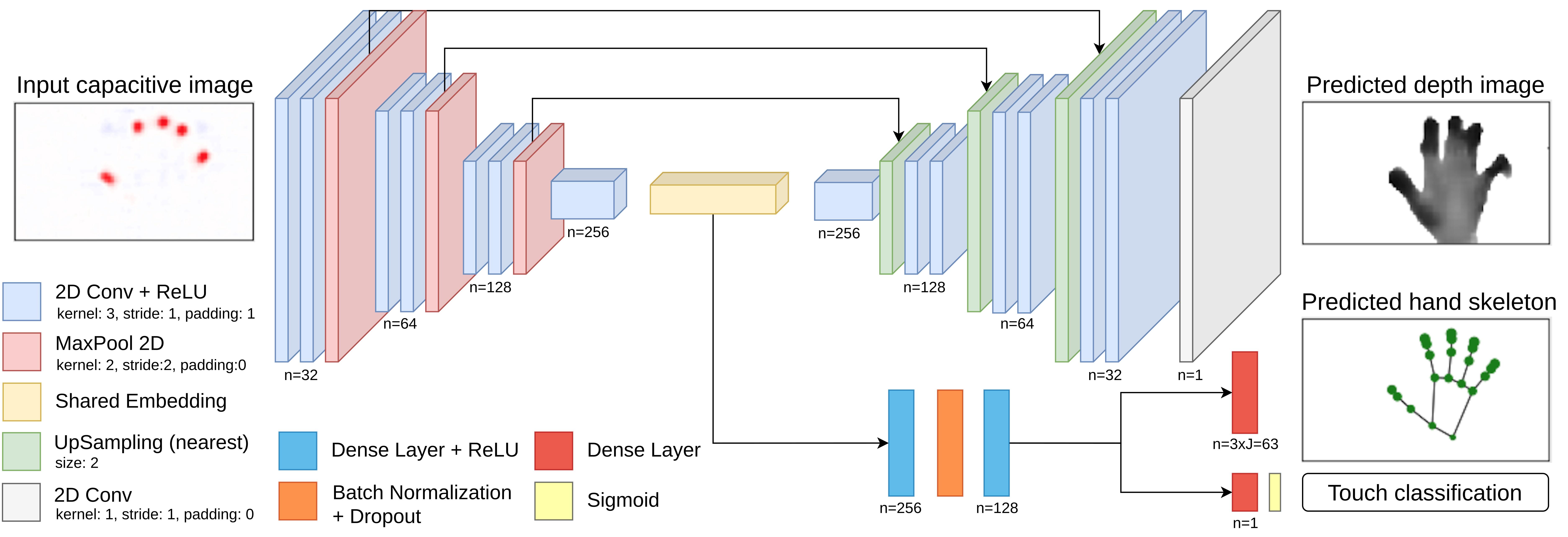
Figure 8: Overview of our architecture. It is a multitask learning framework that takes in a capacitive image as input and predicts the depth image, 3D hand pose, and touch classification for it.
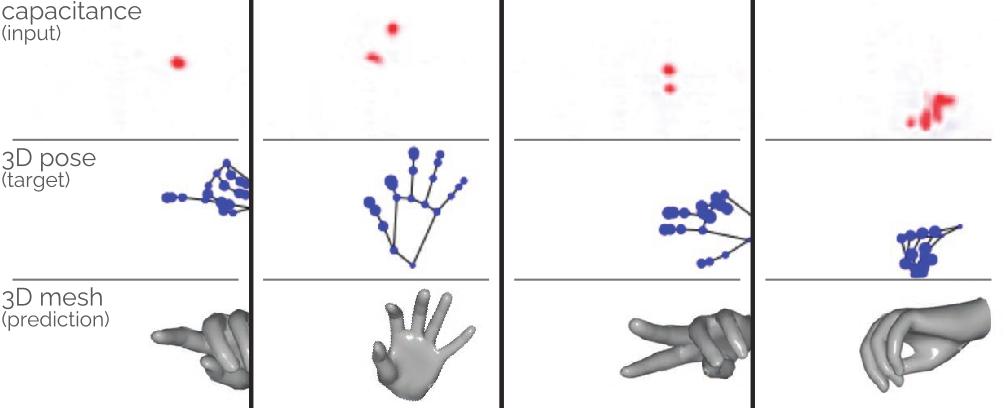
Figure 9: Top: Raw capacitive input images. Middle: Ground-truth hand poses for comparison. Bottom: Hand meshes rendered using skeletons that were estimated by TouchPose.
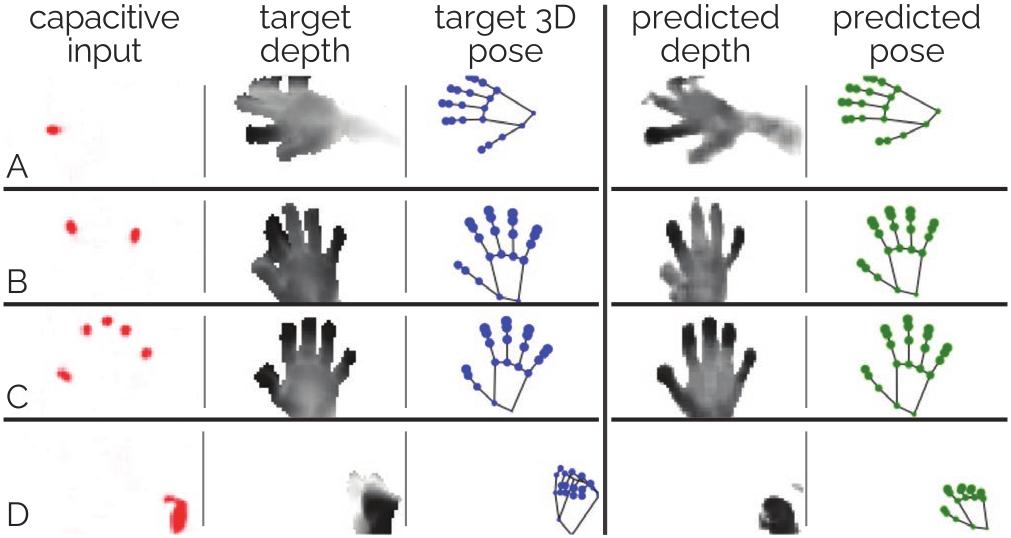
Figure 10: Sample predictions from TouchPose on hand poses that it has not been trained on (Evaluation Protocol 3): (A) index finger, (B) index and pinky, (C) all five fingers, (D) side fist.
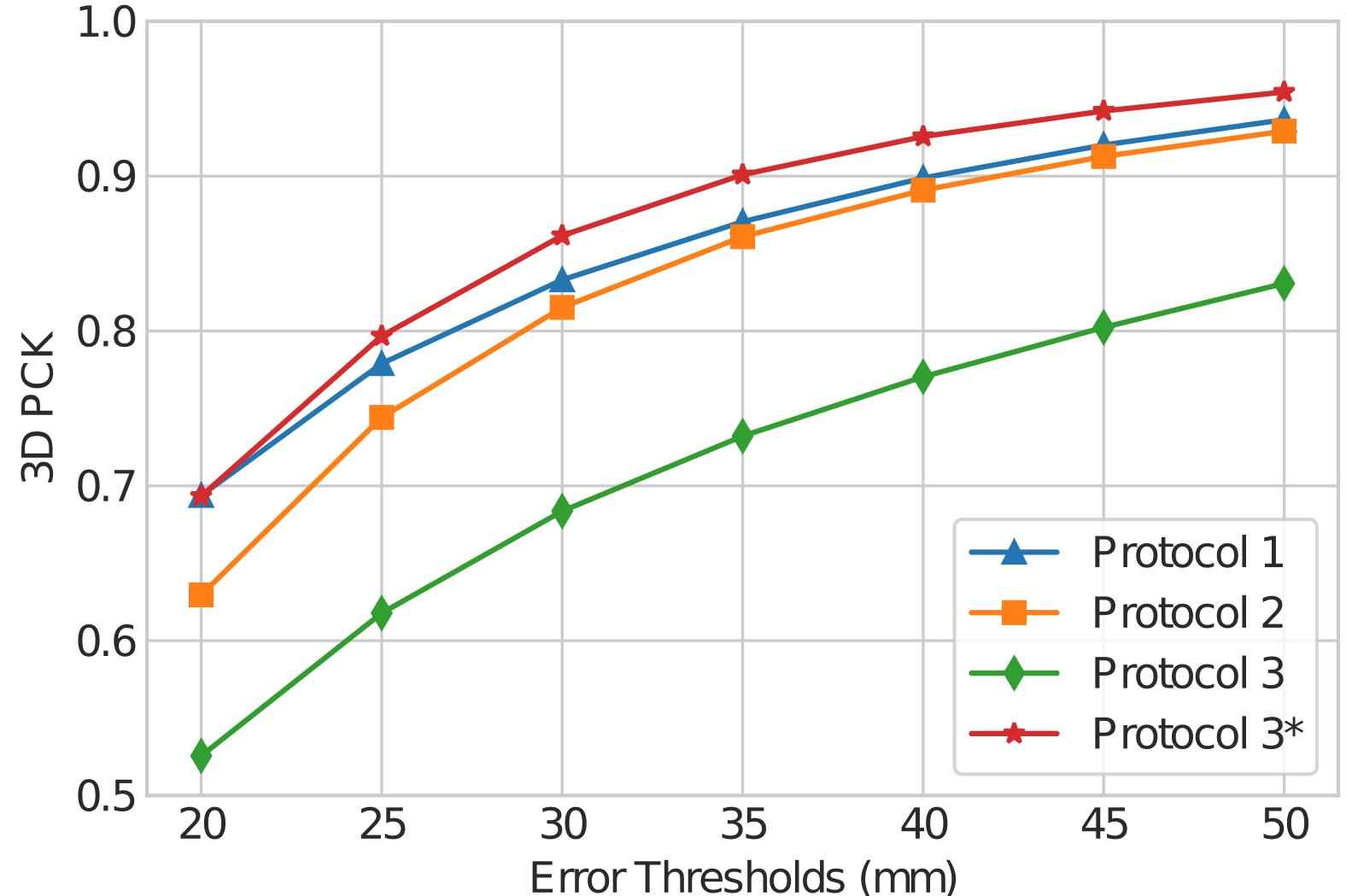
Figure 11: The PCK (percentage of correct 3D keypoints) curve of TouchPose across different evaluation protocols. * denotes accuracy calculated on only fingertip based touch events.
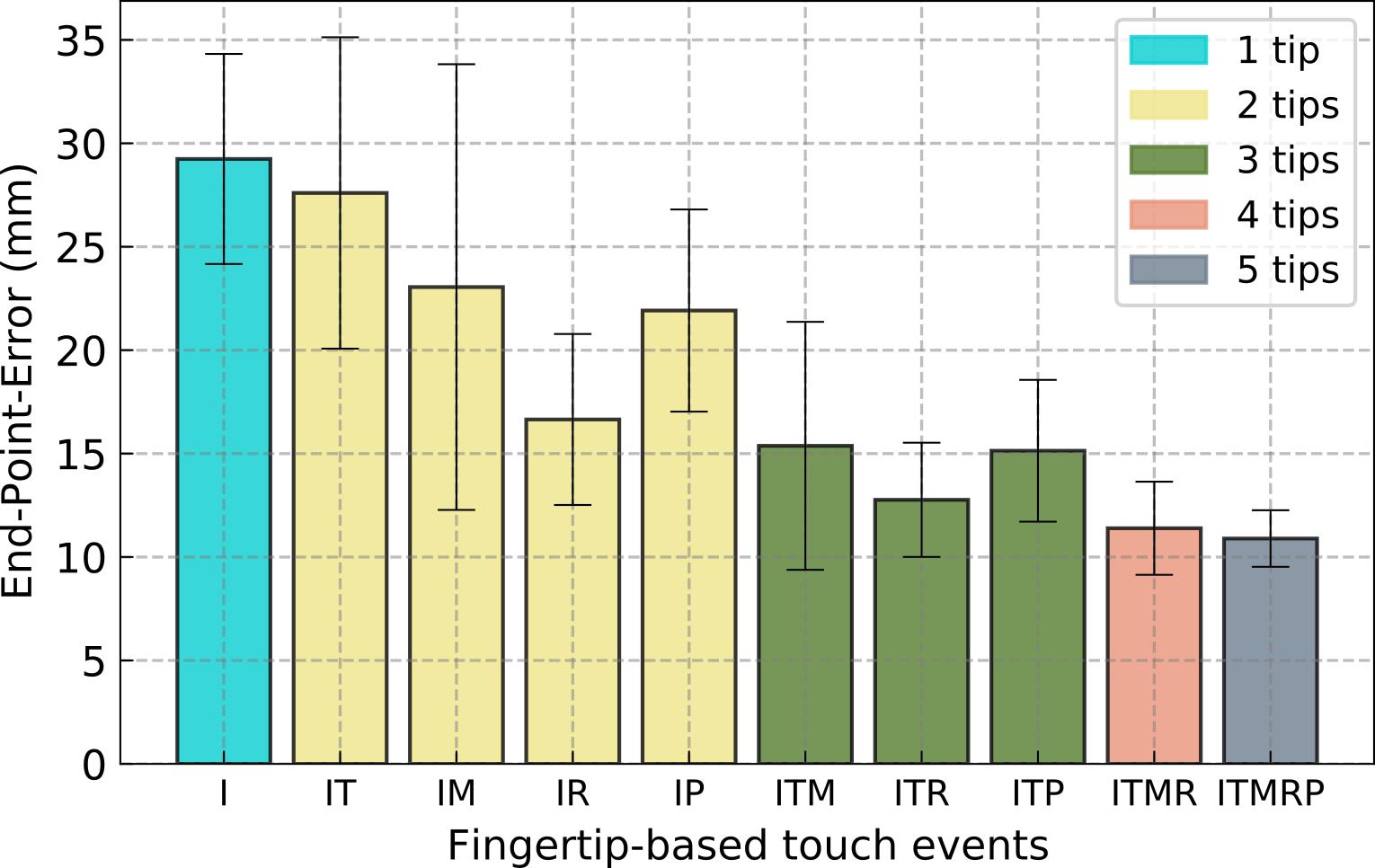
Figure 12: EPE vs. different fingertip touch events under Evaluation Protocol 3. Letters denote the touching fingertips—I: Index, T: Thumb, M: Middle, R: Ring, and P: Pinky. The legend denotes the number of fingertips touching the screen.
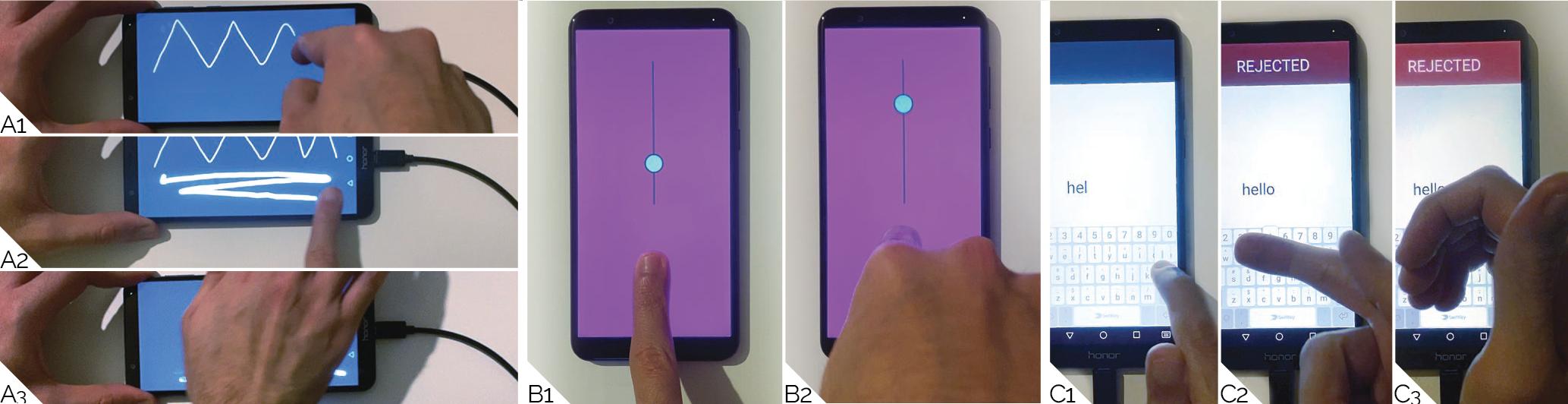
Figure 13: TouchPose can power diverse touch interactions. (A) This finger- and hand part-specific drawing app (A1–2) infers stroke width from attack angle or (A3) smudging. (B) This 3D joystick is quick to operate through finger angle. (C) Inadvertent touch rejection allows (C1) regular typing but rejects (C2) fingers at wrong orientations or (C3) other hand parts.





