EgoPressure
A Dataset for Hand Pressure and Pose Estimation in Egocentric Vision
CVPR 2025 HighlightDepartment of Computer Science, ETH Zürich* equal contribution

Abstract
Touch contact and pressure are essential for understanding how humans interact with objects and offer insights that benefit applications in mixed reality and robotics. Estimating these interactions from an egocentric camera perspective is challenging, largely due to the lack of comprehensive datasets that provide both hand poses and pressure annotations. In this paper, we present EgoPressure, an egocentric dataset that is annotated with high-resolution pressure intensities at contact points and precise hand pose meshes, obtained via our multi-view, sequence-based optimization method. We introduce baseline models for estimating applied pressure on external surfaces from RGB images, both with and without hand pose information, as well as a joint model for predicting hand pose and the pressure distribution across the hand mesh. Our experiments show that pressure and hand pose complement each other in understanding hand-object interactions.
Video
Reference
Yiming Zhao*, Taein Kwon*, Paul Streli*, Marc Pollefeys, and Christian Holz . EgoPressure: A Dataset for Hand Pressure and Pose Estimation in Egocentric Vision. In Conference on Computer Vision and Pattern Recognition 2025 (CVPR).
Marker-less Annotation Method
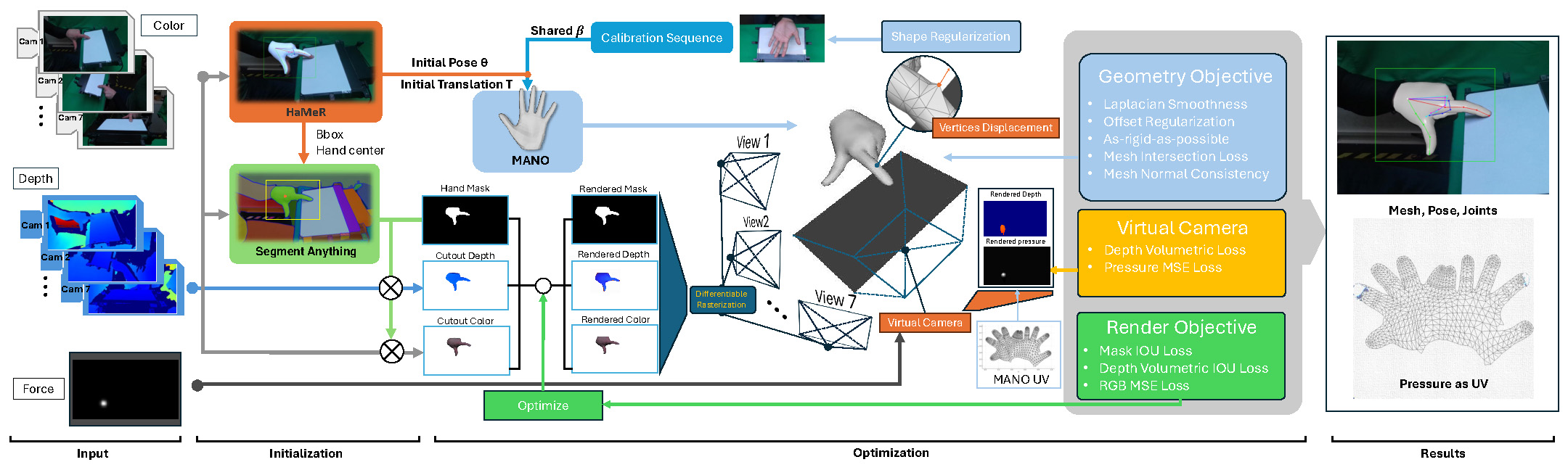
Figure 2: The input for our annotation method consists of RGB-D images captured by 7 static Azure Kinect cameras and the pressure frame from a Sensel Morph touchpad. We leverage Segment-Anything and HaMeR to obtain initial hand poses and masks. We refine the initial hand pose and shape estimates through differentiable rasterization optimization across all static camera views. Using an additional virtual orthogonal camera placed below the touchpad, we reproject the captured pressure frame onto the hand mesh by optimizing the pressure as a texture feature of the corresponding UV map, while ensuring contact between the touchpad and all contact vertices.
Capture setup
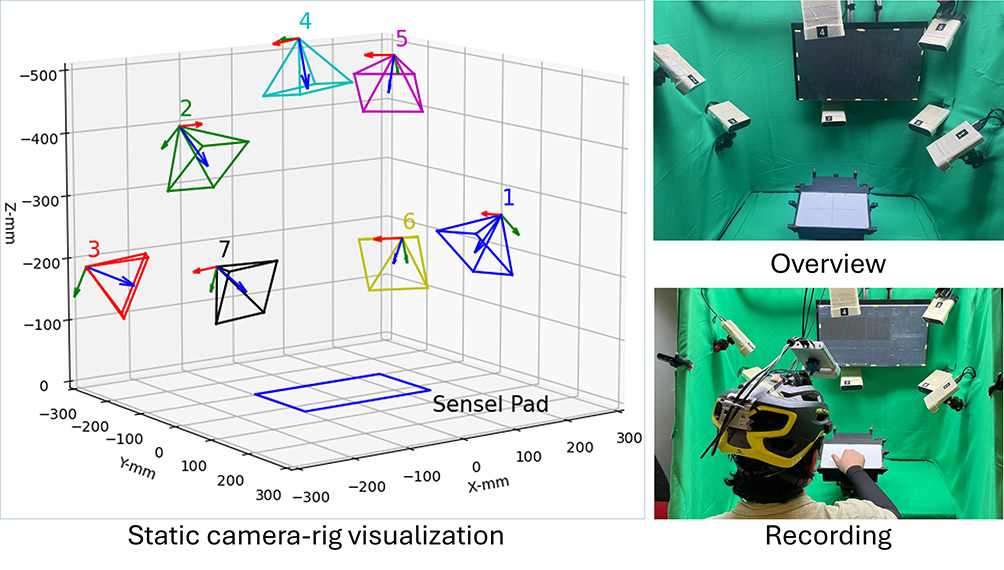
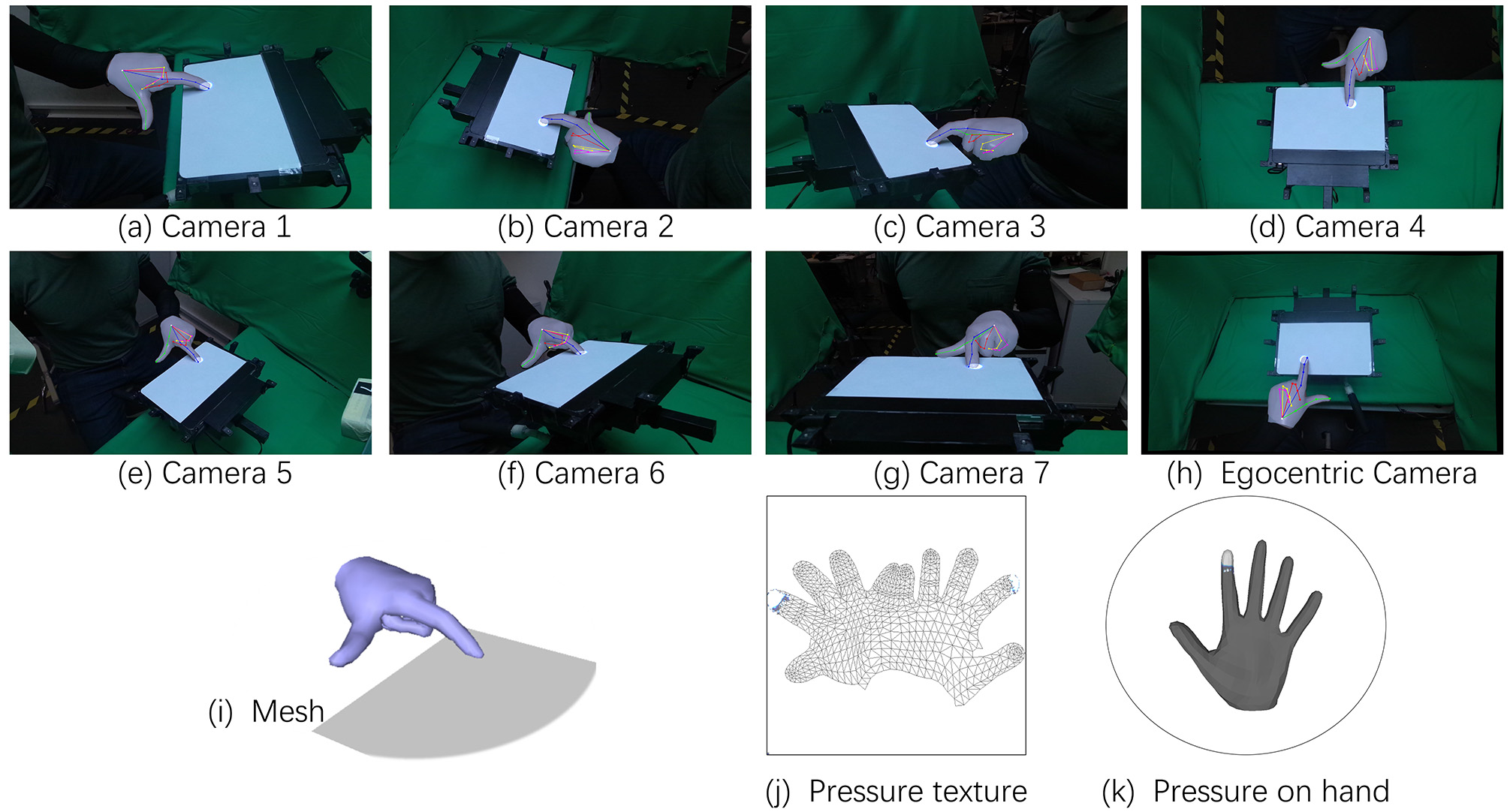
Figure 3: To capture accurate ground-truth labels for hand pose and pressure from egocentric views, we constructed a data capture rig that integrates a pressure-sensitive touchpad (Sensel Morph) for touch and pressure sensing, along with seven static and one head-mounted RGB-D camera (Azure Kinect) to capture RGB and depth images.
![]()
Figure 4: To obtain accurate poses of the head-mounted camera, we attach nine active infrared markers around the Sensel Morph pad in an asymmetric layout. These markers, controlled by the Raspberry Pi CM4, are identifiable in the Azure Kinect’s infrared image using simple thresholding (saturating the range of values of the infrared camera). The markers are turned on simultaneously, allowing for the computation of the camera pose via Perspective-N-Points and enabling an accurate evaluation of the temporal synchronization between cameras and the touchpad.
Dataset overview
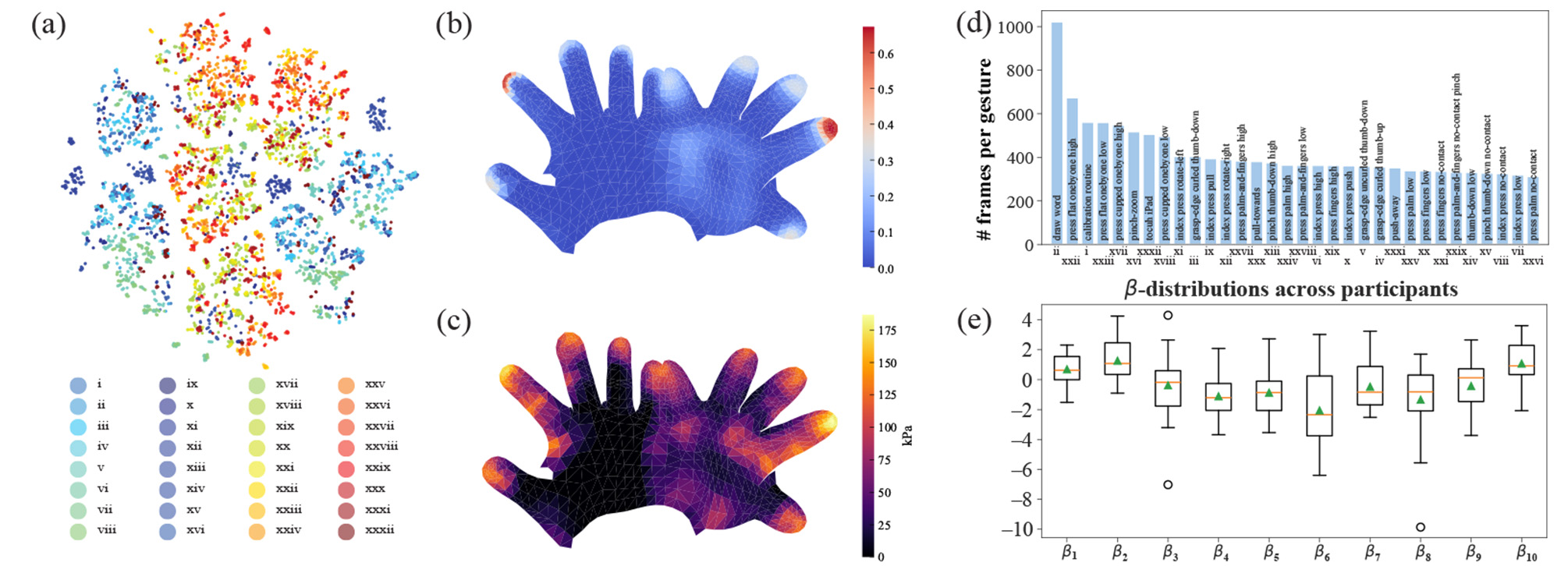
Figure 5: Dataset Statistics. (a) t-SNE visualization of hand pose frames θ over our dataset, with color coding for different gestures. All gestures are listed in Table S5 of the Supp. (b) Ratio of touch frames with contact for each vertex. (c) Maximum pressure over hand vertices across the dataset. (d) Mean length of performed gestures. (e) Distribution of β values across participants.

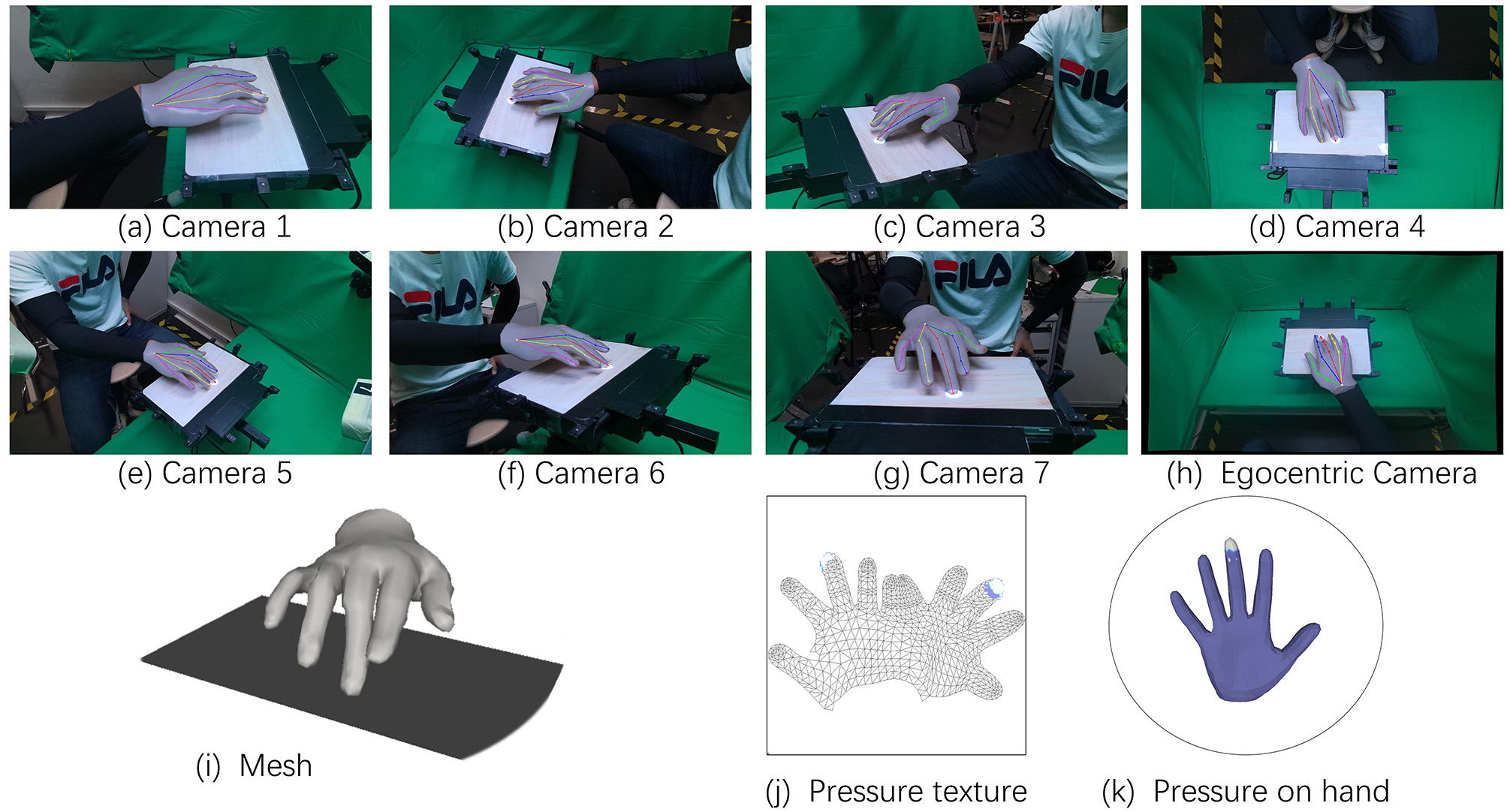
Figure 6: Thumbnail of different poses in egocentric views. The dataset features 21 participants performing 31 distinct gestures, such as touch, drag, pinch, and press, with each hand.
Benchmark

Figure 8: Qualitative results of baseline models. We present the egocentric experiment results in Subfigure (a). In Subfigure (b), both baseline models are trained using camera views 2, 3, 4, and 5. We display the results for one seen view and one unseen view. Additionally, we overlay the 2D keypoints predicted by HaMeR and our annotated ground truth on the input image. For better visualization, the contour of the touch sensing area is also highlighted as a reference.
PressureFormer

Figure 9: PressureFormer uses HaMeR’s hand vertices and image feature tokens to estimate the pressure distribution over the UV map. We employ a differentiable renderer to project the pressure back onto the image plane by texture-mapping it onto the predicted hand mesh.

Figure 10: PressureFormer on data captured with Meta Quest 3. We provide qualitative results demonstrating PressureFormer’s ability to generalize to unseen camera configurations, such as the integrated passthrough sensors of the Quest 3.

Figure 11: Qualitative results of PressureFormer on our dataset. We compare our PressureFormer with both PressureVisionNet and our extended baseline model with HaMeR–estimated 2.5D joint positions. Additionally, we provide visualizations of the hand mesh estimated by HaMeR, alongside the 3D pressure distribution on the hand surface derived from our predicted UV-pressure in the last two columns. Note that we transform the left-hand UV maps into the right-hand format.





