TouchInsight
Uncertainty-aware Rapid Touch and Text Input for Mixed Reality from Egocentric Vision
ACM UIST 2024
Abstract
While passive surfaces offer numerous benefits for interaction in mixed reality, reliably detecting touch input solely from head-mounted cameras has been a long-standing challenge. Camera specifics, hand self-occlusion, and rapid movements of both head and fingers introduce considerable uncertainty about the exact location of touch events. Existing methods have thus not been capable of achieving the performance needed for robust interaction.
In this paper, we present a real-time pipeline that detects touch input from all ten fingers on any physical surface, purely based on egocentric hand tracking. Our method TouchInsight comprises a neural network to predict the moment of a touch event, the finger making contact, and the touch location. TouchInsight represents locations through a bivariate Gaussian distribution to account for uncertainties due to sensing inaccuracies, which we resolve through contextual priors to accurately infer intended user input.
We first evaluated our method offline and found that it locates input events with a mean error of 6.3 mm, and accurately detects touch events (F1=0.99) and identifies the finger used (F1=0.96). In an online evaluation, we then demonstrate the effectiveness of our approach for a core application of dexterous touch input: two-handed text entry. In our study, participants typed 37.0 words per minute with an uncorrected error rate of 2.9% on average.
Video
Reference
Paul Streli, Mark Richardson, Fadi Botros, Shugao Ma, Robert Wang, and Christian Holz . TouchInsight: Uncertainty-aware Rapid Touch and Text Input for Mixed Reality from Egocentric Vision. In Proceedings of ACM UIST 2024.
BibTeX citation
@inproceedings{uist2024-touchinsight, author={Streli, Paul and Richardson, Mark and Botros, Fadi and Ma, Shugao and Wang, Robert and Holz, Christian}, title={TouchInsight: Uncertainty-aware Rapid Touch and Text Input for Mixed Reality from Egocentric Vision}, year={2024}, pages={1--16}, isbn = {9798400706288}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, doi = {https://doi.org/10.1145/3654777.3676330}, booktitle = {Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST)} }
Sources of Uncertainty
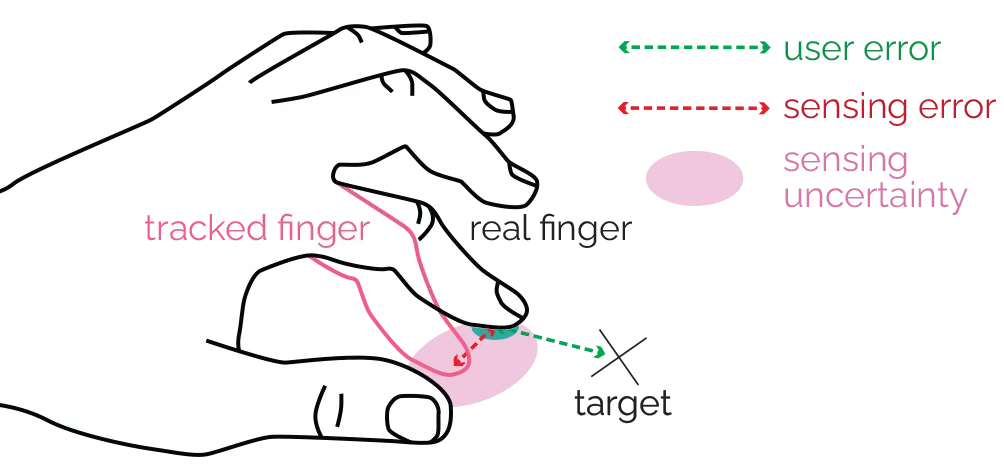
Figure 2: For a single touch input event, the offset between the target and the finger endpoint can be considered as user error. Due to inaccuracies in hand tracking, the endpoint of a tracked finger might additionally deviate from the actual finger location. We refer to this as sensing error, which introduces sensing uncertainty about the touch location.
Method
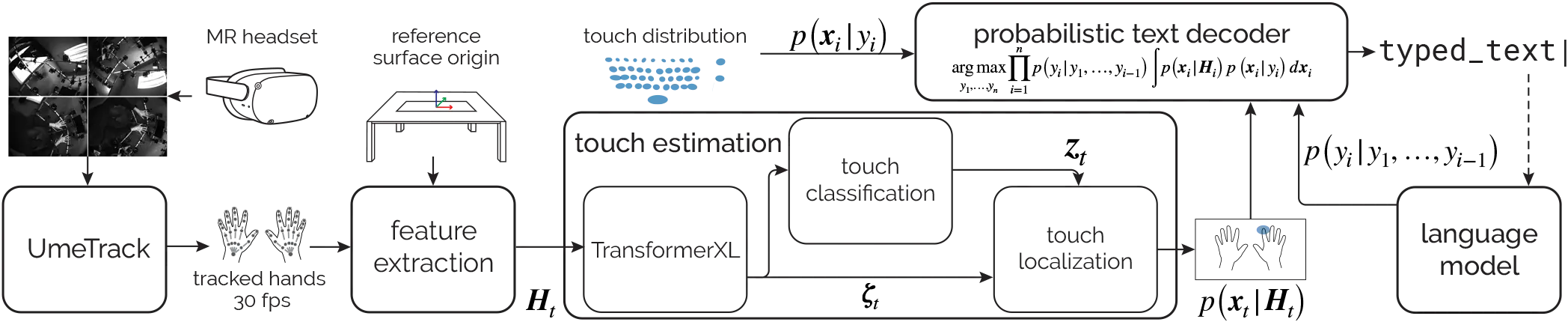
Figure 3: Overview of our framework to enable text entry on physical surfaces in Mixed Reality. Our touch estimation network receives hand-tracking feature sequences, Ht, as input. The features are derived from hand poses tracked from egocentric views via the headset’s cameras and are normalized relative to a coordinate system anchored to a surface-aligned virtual keyboard. The network estimates the occurrence of touch events, the identity of the touching finger zt, and a bivariate Gaussian distribution for the touch location p(xt | Ht). Our probabilistic text decoder fuses this distribution with p(xi | yi)—capturing the distribution of touch points for intended key presses—and a context prior based on input history from a language model p(yi | y1, …, yi-1).
Evaluation

Figure 4: The figure shows the apparatus for our online text entry evaluation (a) as well as the evaluation interface for MIDAIR (b), GREEDYSURF (c), and BEAMSURF (d).
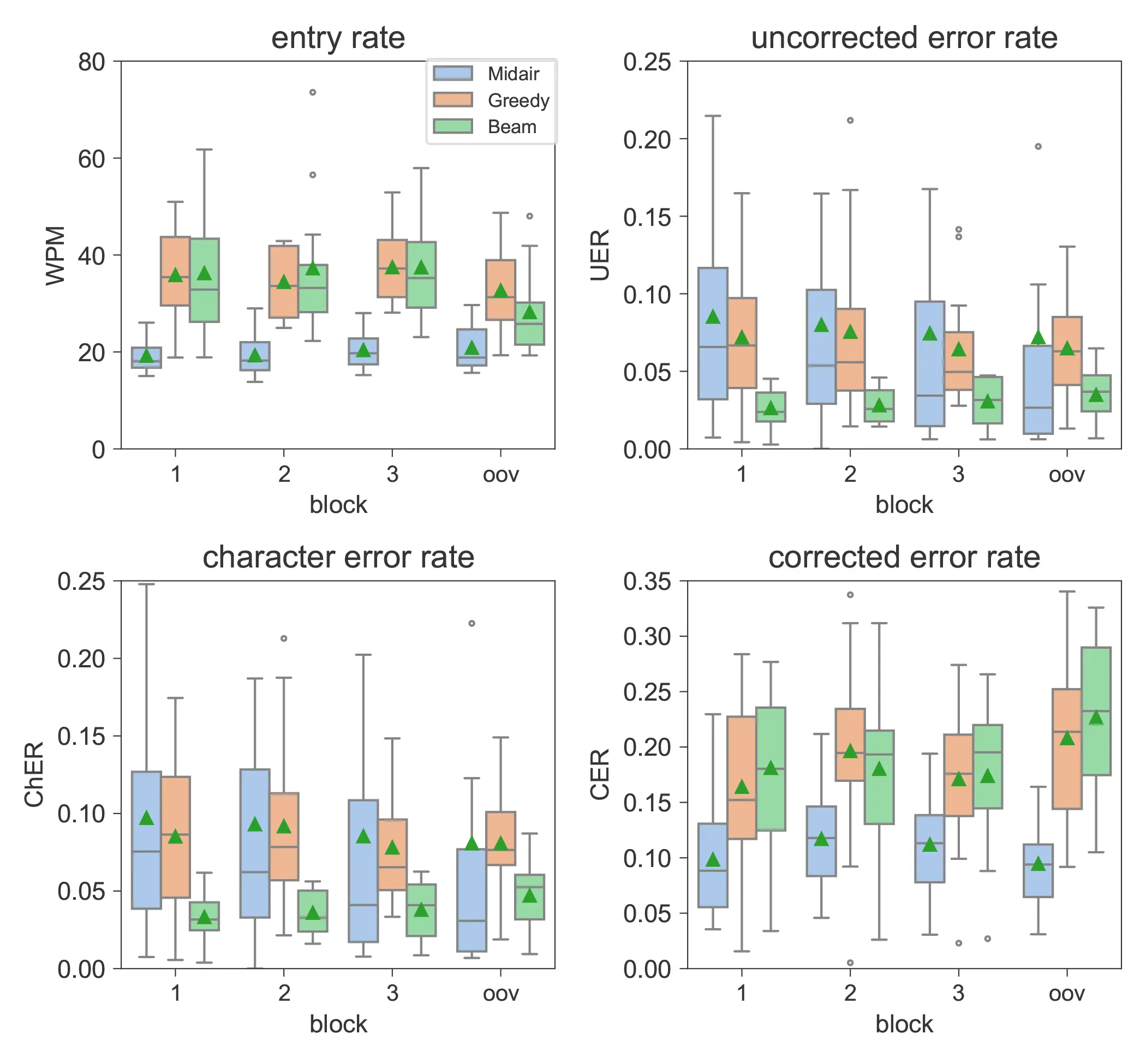
Figure 5: Boxplot of the mean text entry rate in WPM and error rates (UER, ChER, CER) across participants for MIDAIR, GREEDYSURF, and BEAMSURF, and BLOCK 1, BLOCK 2, BLOCK 3, and BLOCK OOV.
Acknowledgments
We thank Yangyang Shi, Bradford Snow, Pinhao Guo, and Jingming Dong for helpful discussions and comments, as well as the participants of our user studies.