EgoPoser
Robust Real-Time Egocentric Pose Estimation from Sparse and Intermittent Observations Everywhere
ECCV 2024Department of Computer Science, ETH Zürich
Abstract
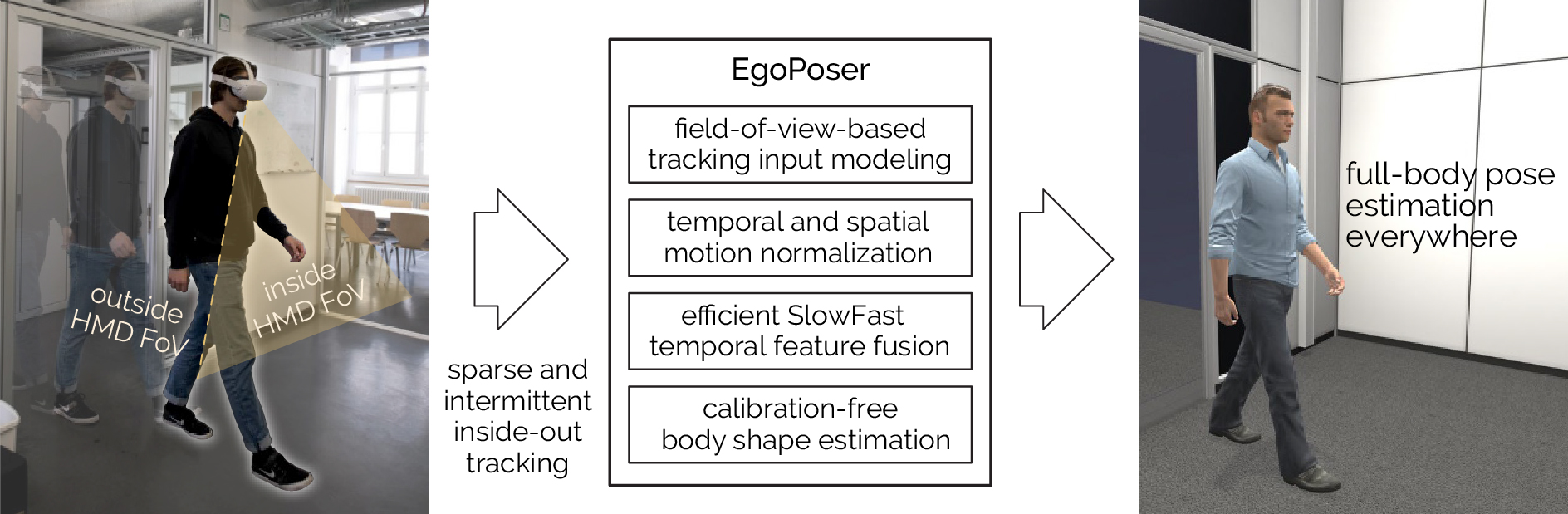
Full-body egocentric pose estimation from head and hand poses alone has become an active area of research to power articulate avatar representations on headset-based platforms. However, existing methods over-rely on the indoor motion-capture spaces in which datasets were recorded, while simultaneously assuming continuous joint motion capture and uniform body dimensions. We propose EgoPoser to overcome these limitations with four main contributions. 1) EgoPoser robustly models body pose from intermittent hand position and orientation tracking only when inside a headset’s field of view. 2) We rethink input representations for headset-based ego-pose estimation and introduce a novel global motion decomposition method that predicts full-body pose independent of global positions. 3) We enhance pose estimation by capturing longer motion time series through an efficient SlowFast module design that maintains computational efficiency. 4) EgoPoser generalizes across various body shapes for different users. We experimentally evaluate our method and show that it outperforms state-of-the-art methods both qualitatively and quantitatively while maintaining a high inference speed of over 600fps. EgoPoser establishes a robust baseline for future work where full-body pose estimation no longer needs to rely on outside-in capture and can scale to large-scale and unseen environments.
Video
Reference
Jiaxi Jiang, Paul Streli, Manuel Meier, and Christian Holz . EgoPoser: Robust Real-Time Egocentric Pose Estimation from Sparse and Intermittent Observations Everywhere. In European Conference on Computer Vision 2024 (ECCV).
BibTeX citation
@inproceedings{jiang2024egoposer, title={EgoPoser: Robust real-time egocentric pose estimation from sparse and intermittent observations everywhere}, author={Jiang, Jiaxi and Streli, Paul and Meier, Manuel and Holz, Christian}, booktitle={European Conference on Computer Vision}, year={2024}, organization={Springer} }
Method
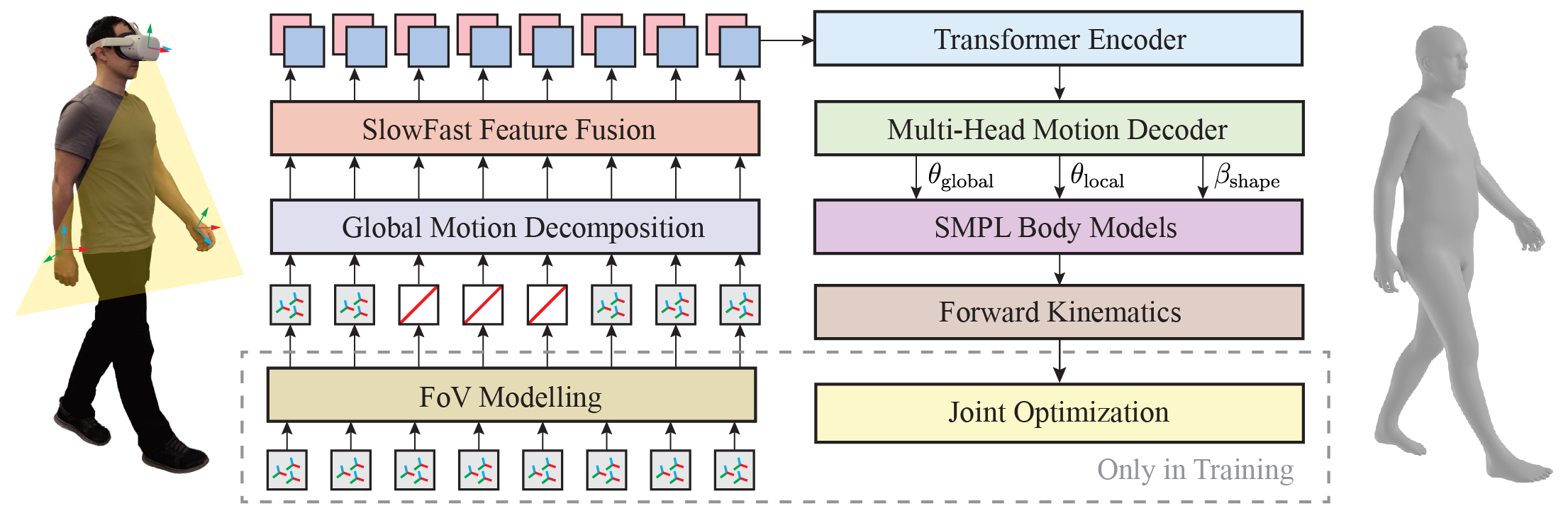
Figure 2: The architecture of EgoPoser for full-body pose estimation from an MR device. We mask the tracking signals according to realistic FoV modelling during training. Our proposed global motion decomposition strategy enables us to decompose global motion from input tracking signals, making the model robust to different user positions. We sample these signals at different rates, capturing both dense nearest information and sparse but longer information. The resulting preprocessed signals are then fused by the SlowFast Fusion module and fed into a Transformer Encoder. The Multi-Head Motion Decoder outputs parameters for global localization, local body pose, and body shape prediction. Given N=80 frames as input, we generate the last frame as the full-body representation for each timestamp, facilitating real-time applications.
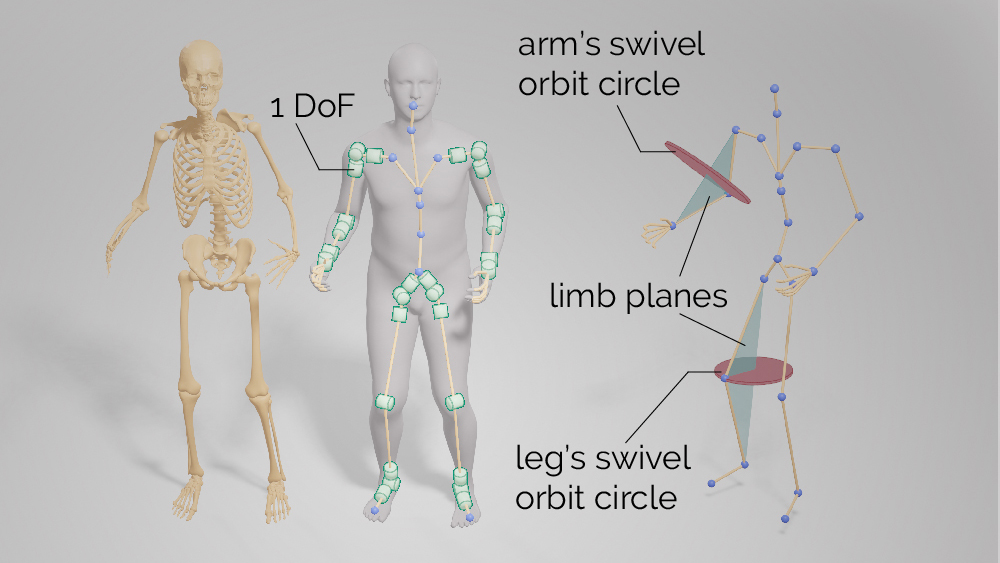
1) Field-of-view modeling
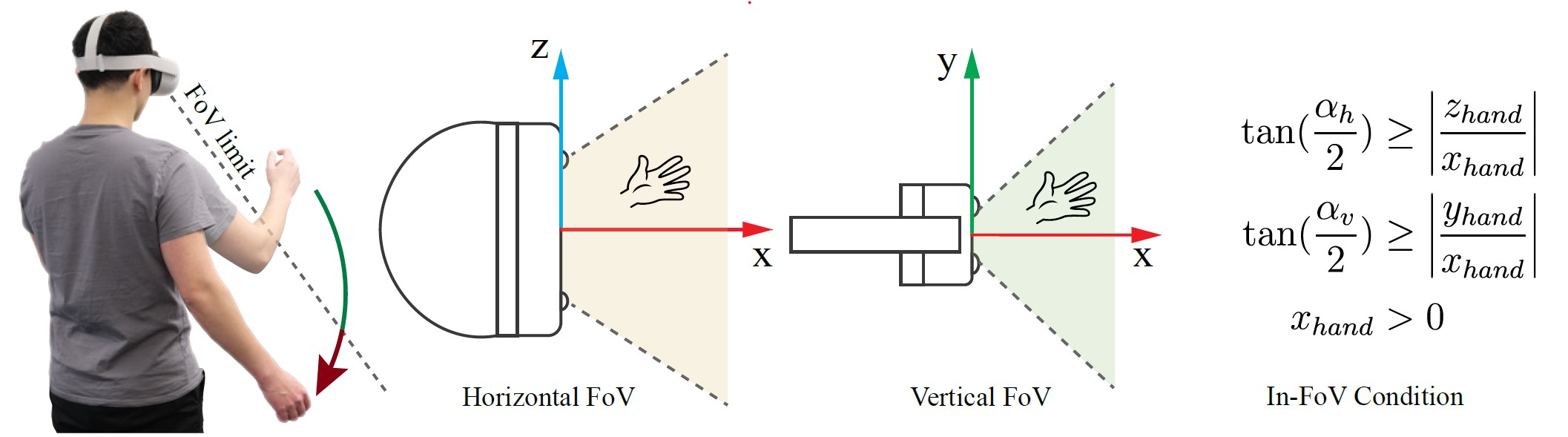
Figure 3: An illustration of an HMD’s field of view and in-FoV conditions. Previous work does not adequately address the inherent limitations of the inside-out hand tracking on today’s state-of-the-art headsets such as Apple Vision Pro, Meta Quest 2/3/Pro, and HoloLens 2. Based on the head pose, which determines the viewing angle of the cameras mounted on the headset, and the relative position of the hands, we simulate hand tracking failures for headsets with varying FoVs.
2) Global motion decomposition
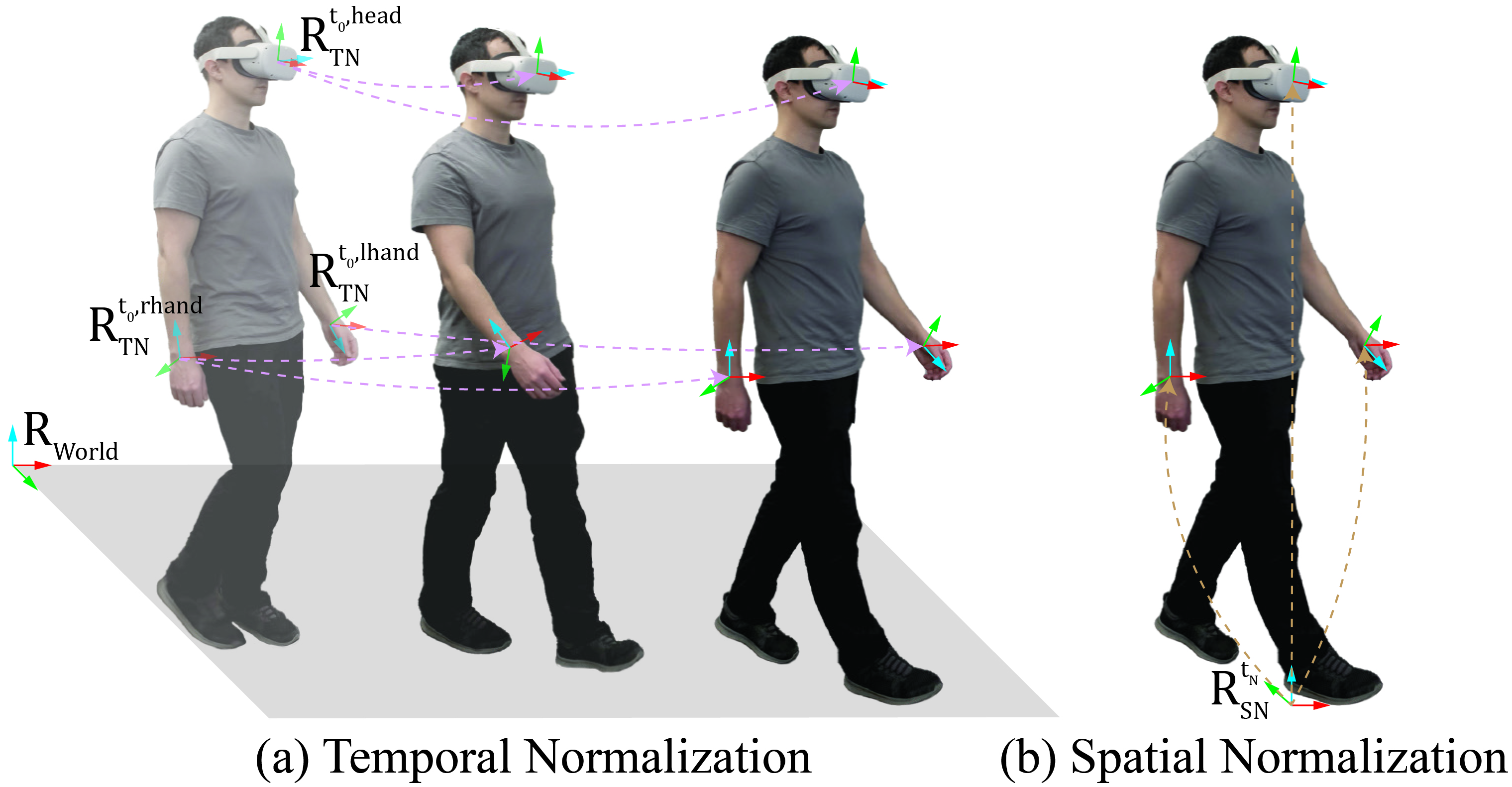
Figure 4: An illustration of global motion decomposition via temporal and spatial normalizations. Existing methods tend to overfit to the training data due to the global input representation of the neural network, while we emphasize the significance of position-invariant pose estimation.
3) SlowFast feature fusion
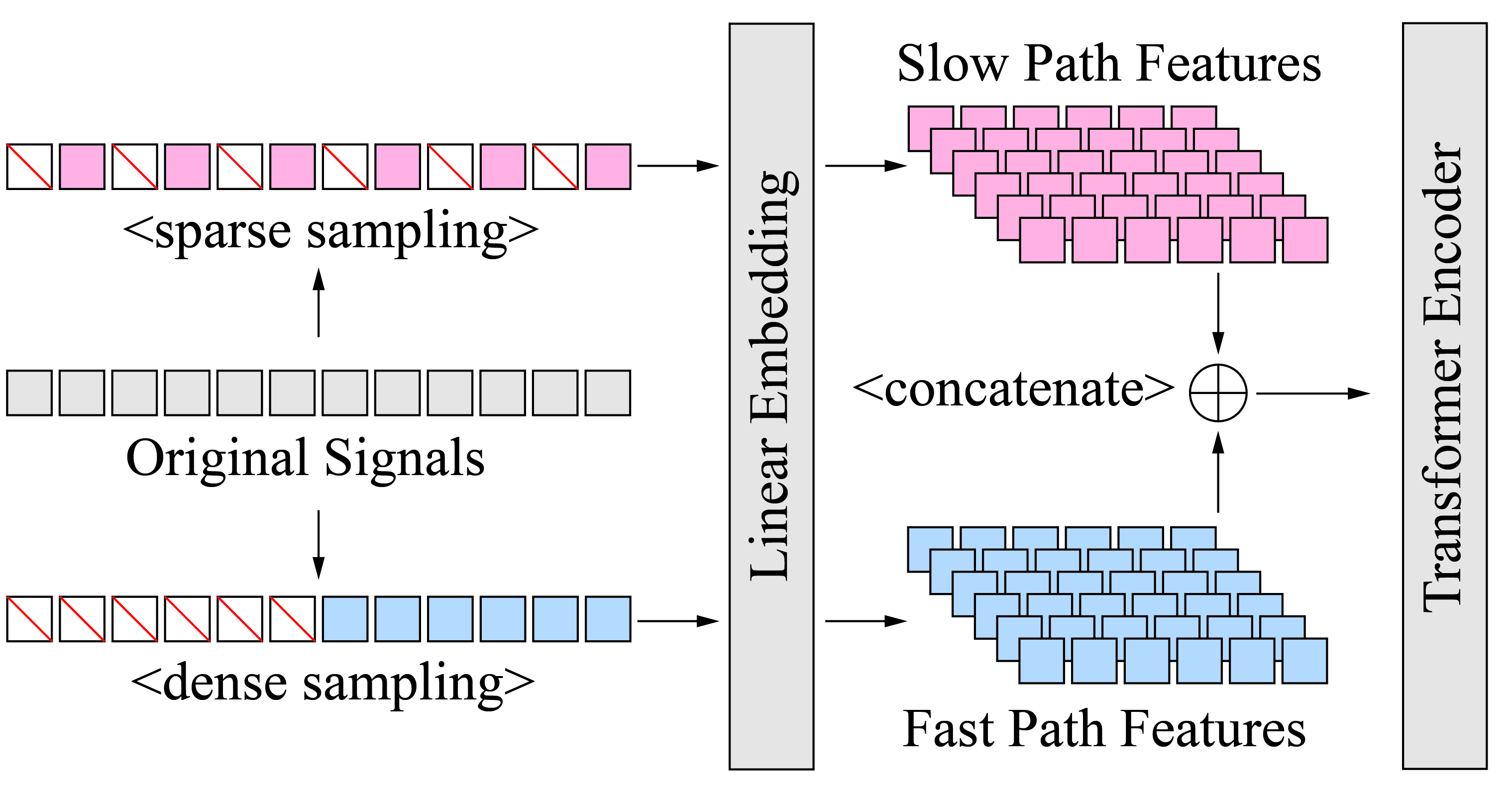
Figure 5: SlowFast feature fusion module. Original signals are sparsely and densely sampled and then concatenated, thus improving prediction accuracy without increasing the computational burden.
4) Body shape estimation
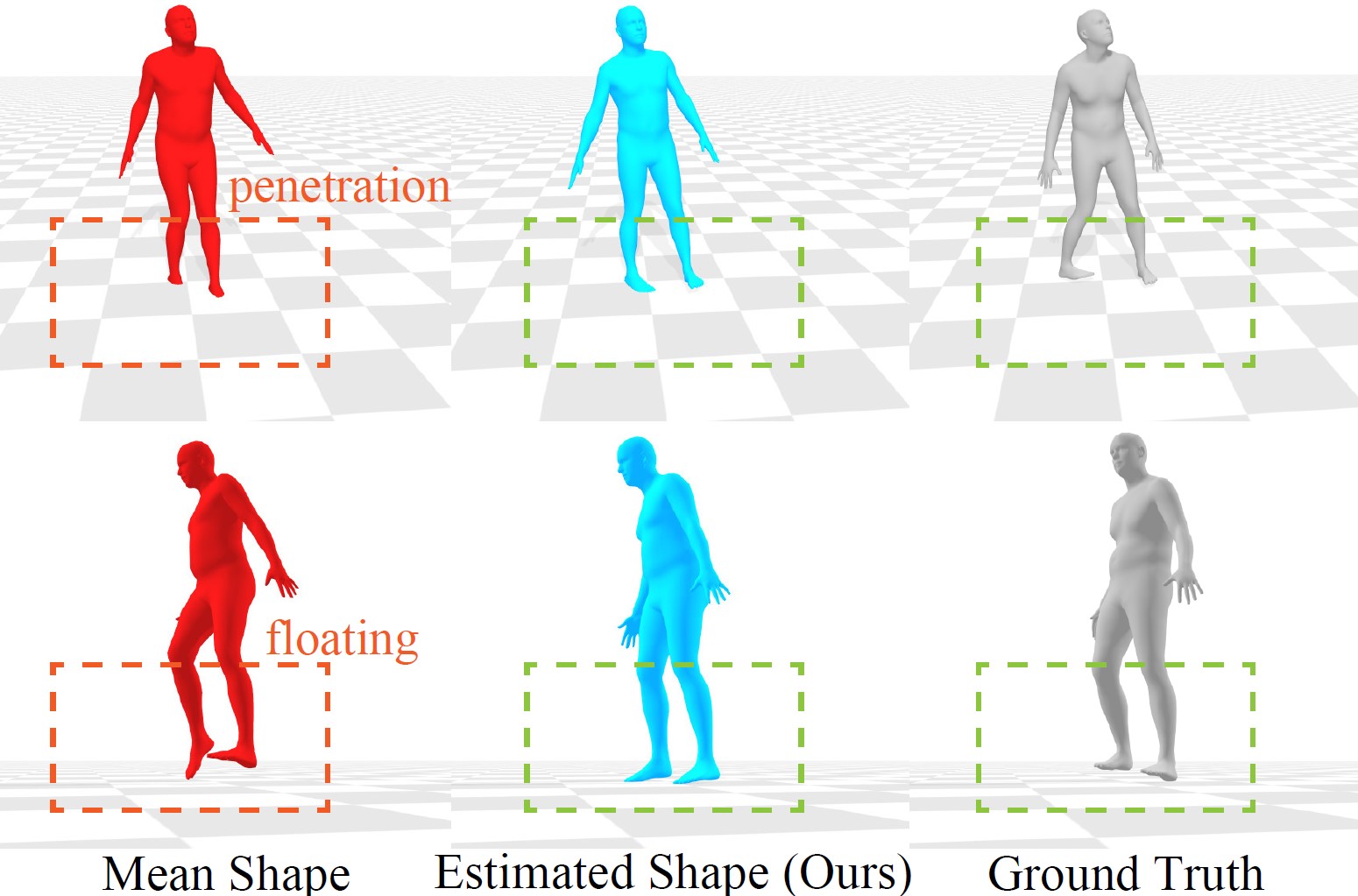
Figure 6: Visual comparison between results using the mean shape and estimated shape. Existing methods only account for a mean body shape and disregard the natural variations in body shapes across different people. This limitation prevents the model from adapting to real-world inputs and accurately representing the user’s body. Besides, our method also reduces penetration and floating.
Results

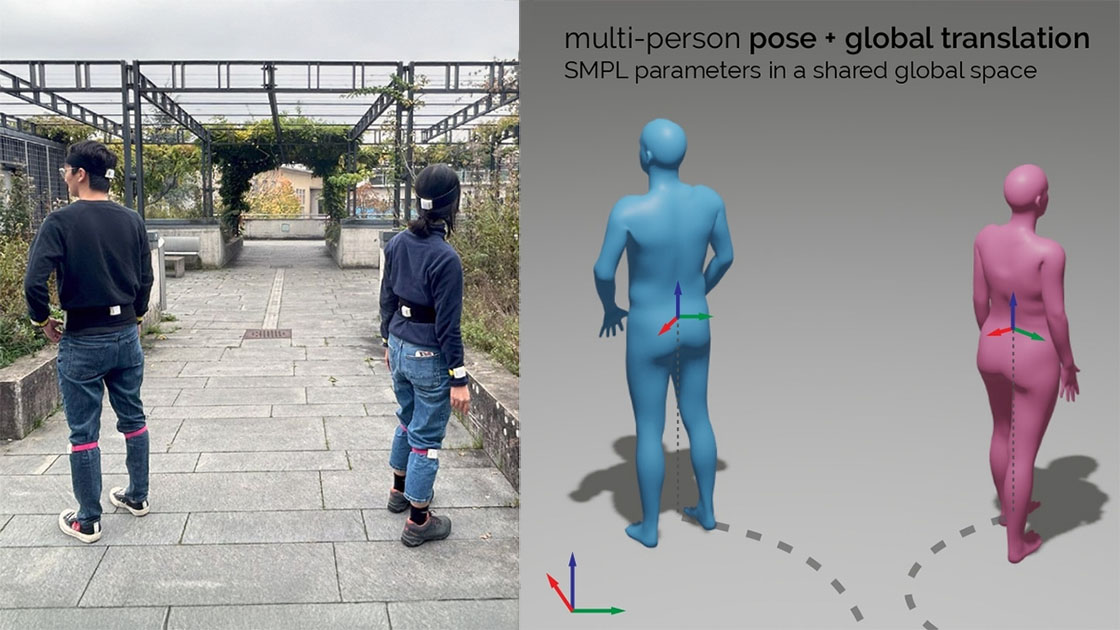
Figure 7: Visual comparisons on the HPS dataset. The results on the HPS dataset, encompassing motion data both in close proximity to the origin and at more distant points, demonstrate the robustness of our method across various spatial contexts. This is particularly noteworthy given that our model was exclusively trained on the indoor AMASS dataset.