Preference-Guided Prompt Optimization
Prompt Optimization for Image Generation
ACM CHI 2026Department of Computer Science, ETH Zürich
Abstract
Generative models are increasingly powerful, yet users struggle to guide them through prompts. The generative process is difficult to control and unpredictable, and user instructions may be ambiguous or under-specified. Prior prompt refinement tools heavily rely on human effort, while prompt optimization methods focus on numerical functions and are not designed for human-centered generative tasks, where feedback is better expressed as binary preferences and demands convergence within few iterations. We present APPO, a preference-guided prompt optimization algorithm. Instead of iterating prompts, users only provide binary preferential feedback. APPO adaptively balances its strategies between exploiting user feedback and exploring new directions, yielding effective and efficient optimization. We evaluate APPO on image generation, and the results show APPO enables achieving satisfactory outcomes in fewer iterations with lower cognitive load than manual prompt editing. We anticipate APPO will advance human-AI collaboration in generative tasks by leveraging user preferences to guide complex content creation.
Reference
Zhipeng Li, Yi-Chi Liao, and Christian Holz . Preference-Guided Prompt Optimization for Image Generation. In Proceedings of ACM CHI 2026.
Workflow
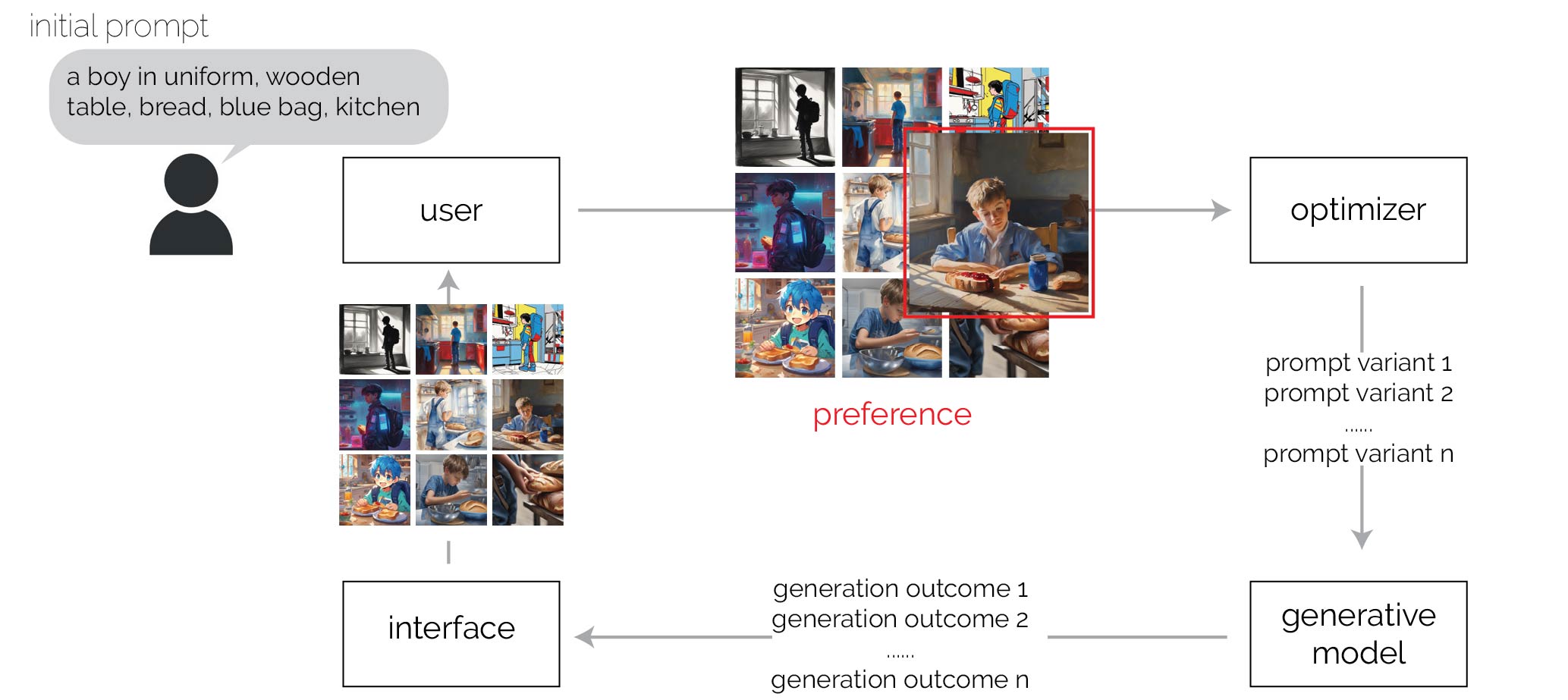
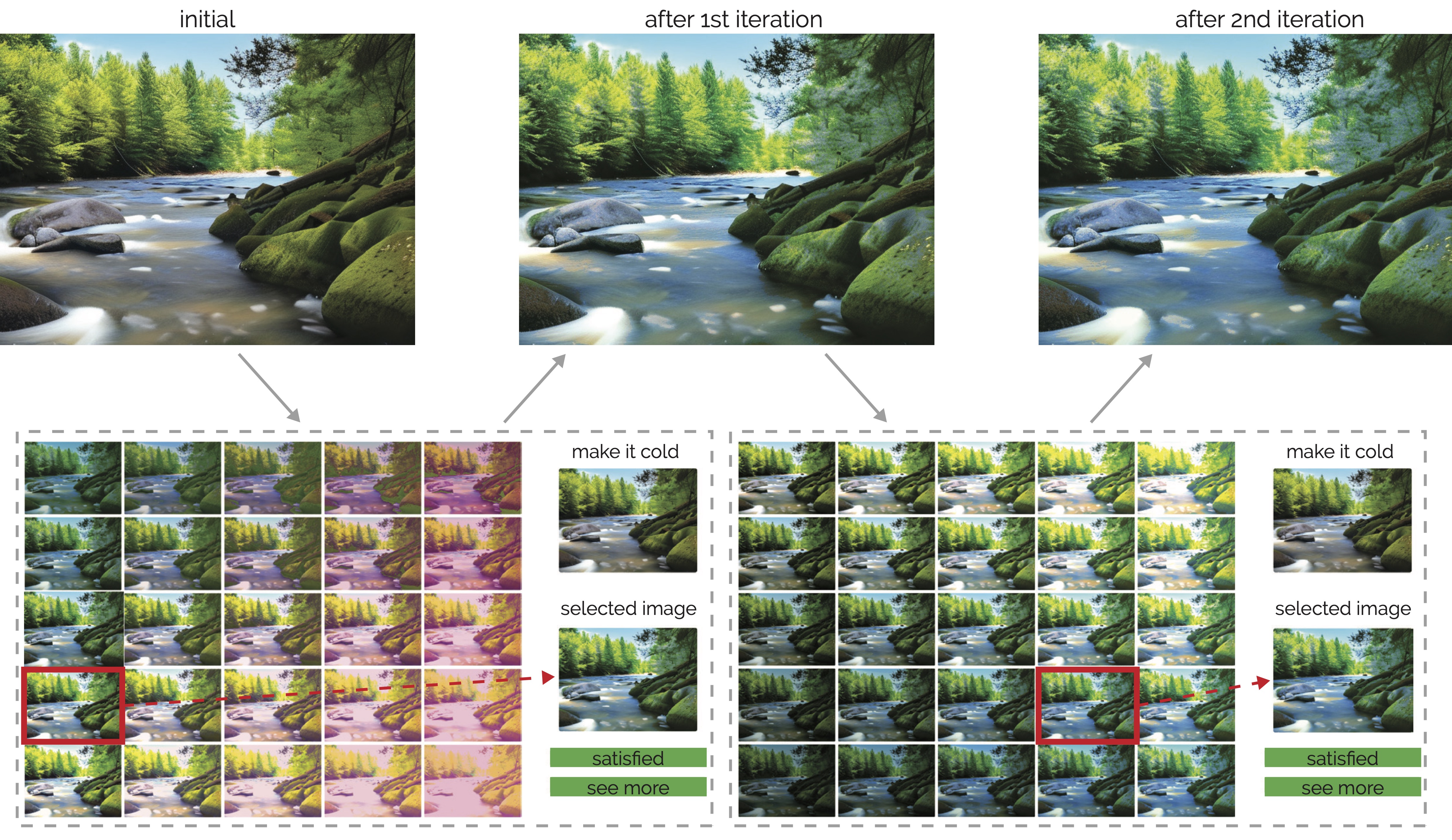
Figure 2: Preference-driven generation workflow enabled by APPO, with image generation as an example. The user begins with an initial prompt specifying the objects to be included in the generated images (top left). In the first iteration, the optimizer expands this prompt to explore diverse possibilities and generate multiple prompt variants (right). The generative model then produces outputs corresponding to these variants (down), which are presented to the user in a gallery (left). The user selects their preferred results (up), which are then fed into the optimizer who infers their preferences to generate refined prompts. These refined prompts are used by the generative model to produce new outputs, which are further evaluated by the user in subsequent iterations.
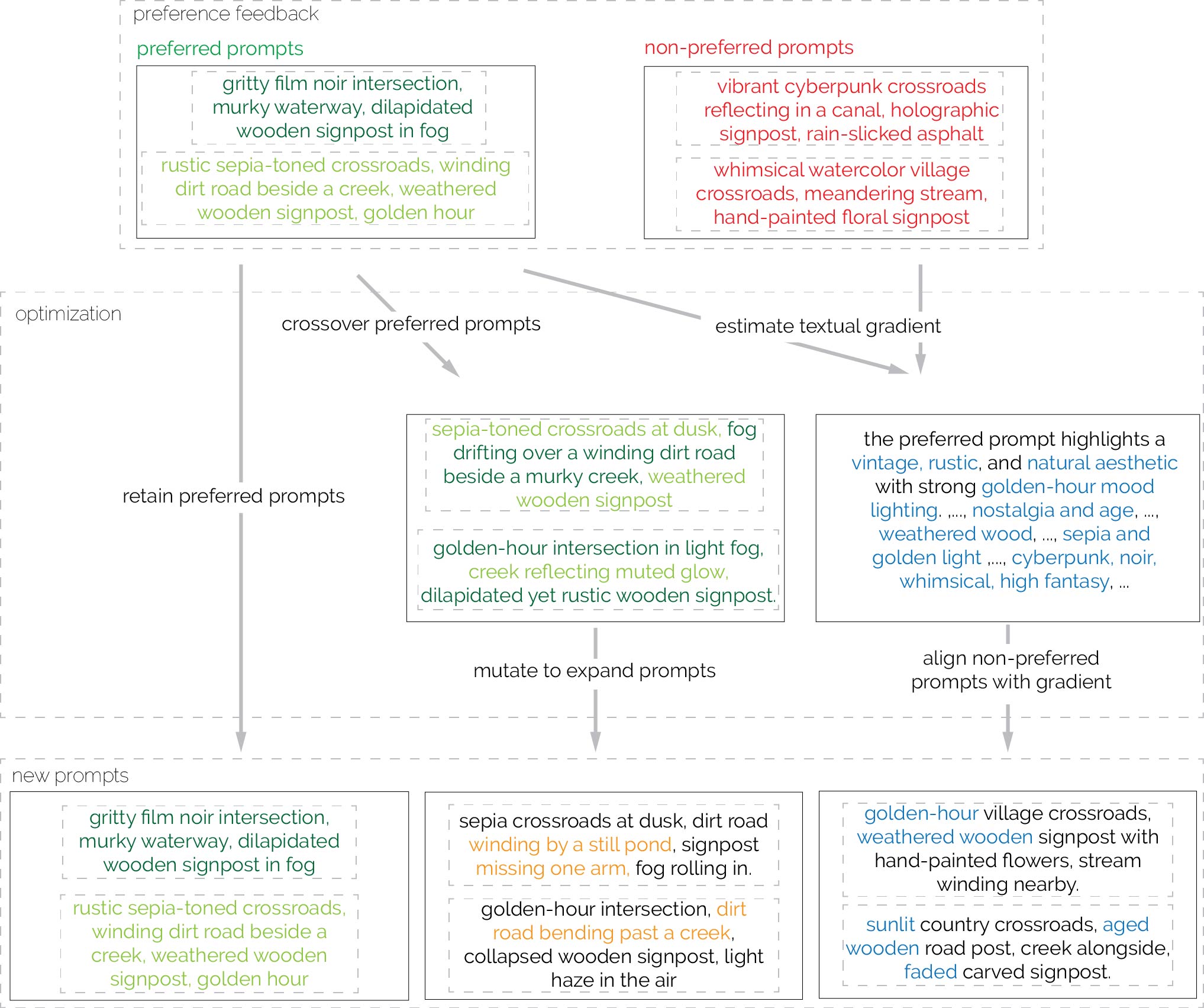
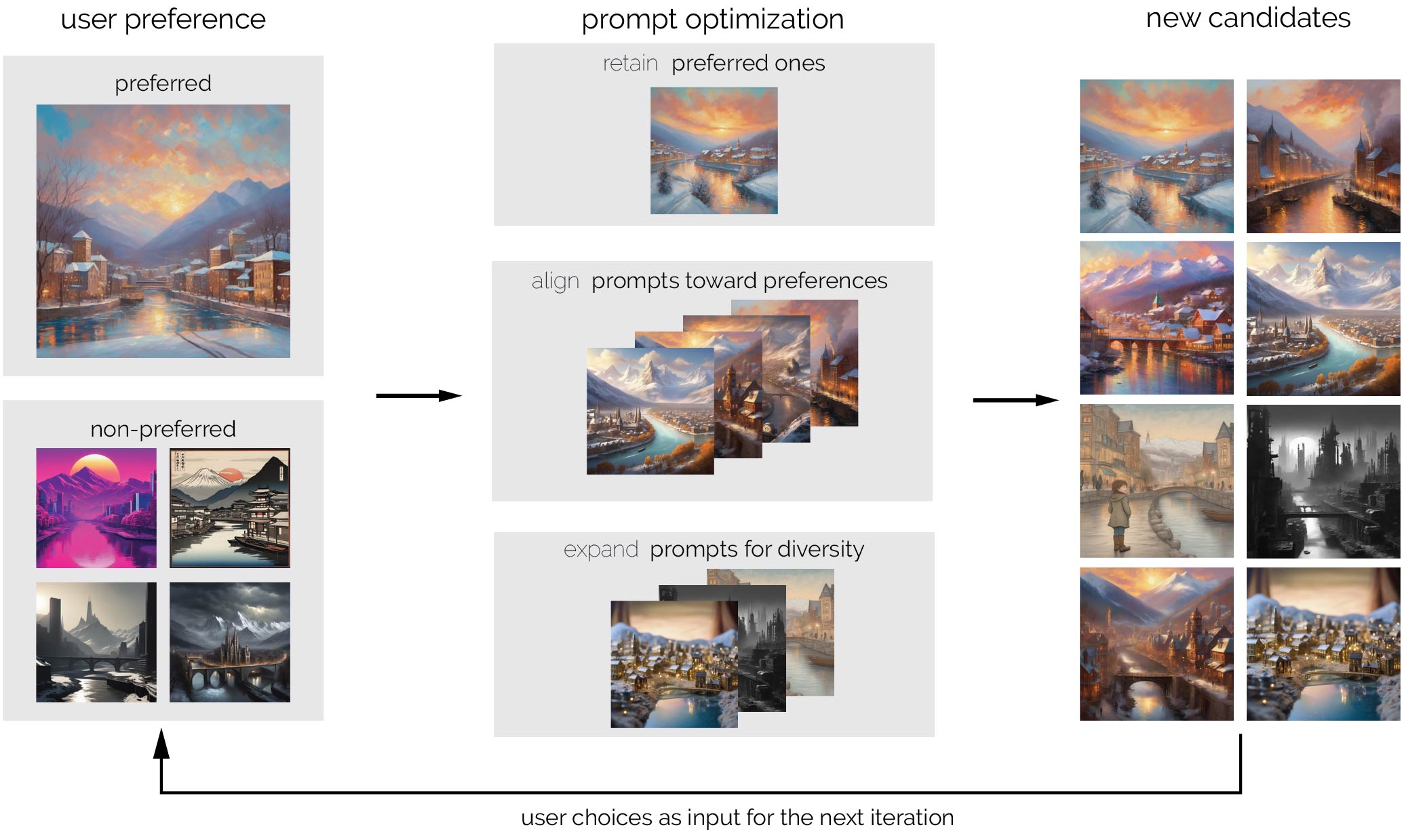
Figure 3: The concept of optimization methods behind APPO with a concrete example. In each iteration, APPO takes the preferred prompts (green) and non-preferred prompts (red) from the previous iteration as input. Three strategies are applied: It first retains the preferred prompts. In parallel, the expansion strategy applies evolutionary operations to explore new prompts. This begins with crossover, mixing elements of the preferred prompts (words in different green colors), followed by mutation to generate additional prompts (orange). Simultaneously, the alignment strategy estimates the textual gradient from both preferred and non-preferred prompts to identify elements generally favored by the user (blue). This gradient is then applied to non-preferred prompts to better align them with user preferences. Finally, all of the three retainment, expansion, and alignment prompts form the set of prompts for the next iteration.
Example results from user study

Figure 4: Example of generation results in close-ended tasks by participants using APPO. During the study, the participant was provided with the target image, and they started with inputing an initial prompt, and using APPO to get their satisfied results.

Figure 5: Example of generation results in open-ended tasks by participants using APPO. Participants started with a general idea in their mind, and achieve these satisfied results using APPO.