Group Inertial Poser
Multi-Person Pose and Global Translation from Sparse Inertial Sensors and Ultra-Wideband Ranging
ICCV 2025Department of Computer Science, ETH Zürich
Abstract
Tracking human full-body motion using sparse wearable inertial measurement units (IMUs) overcomes the limitations of occlusion and instrumentation of the environment inherent in vision-based approaches. However, purely IMU-based tracking compromises translation estimates and accurate relative positioning between individuals, as inertial cues are inherently self-referential and provide no direct spatial reference for others. In this paper, we present a novel approach for robustly estimating body poses and global translation for multiple individuals by leveraging the distances between sparse wearable sensors — both on each individual and across multiple individuals. Our method Group Inertial Poser estimates these absolute distances between pairs of sensors from ultra-wideband ranging (UWB) and fuses them with inertial observations as input into structured state-space models to integrate temporal motion patterns for precise 3D pose estimation. Our novel two-step optimization further leverages the estimated distances for accurately tracking people’s global trajectories through the world. We also introduce GIP-DB, the first IMU+UWB dataset for two-person tracking, which comprises 200 minutes of motion recordings from 14 participants. In our evaluation, Group Inertial Poser outperforms previous state-ofthe-art methods in accuracy and robustness across synthetic and real-world data, showing the promise of IMU+UWB based multi-human motion capture in the wild.
Video
Reference
Ying Xue, Jiaxi Jiang, Rayan Armani, Dominik Hollidt, Yi-Chi Liao, and Christian Holz. Group Inertial Poser: Multi-Person Pose and Global Translation from Sparse Inertial Sensors and Ultra-Wideband Ranging. In International Conference on Computer Vision 2025 (ICCV).
BibTeX citation
@inproceedings{xue2025groupinertialposer, author = {Xue, Ying and Jiang, Jiaxi and Armani, Rayan and Hollidt, Dominik and Liao, Yi-Chi and Holz, Christian}, title = {{Group Inertial Poser}: Multi-Person Pose and Global Translation from Sparse Inertial Sensors and Ultra-Wideband Ranging}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}, pages = {24910--24921}, year = {2025}, publisher = {IEEE}, address = {New Orleans, LA, USA}, doi = {10.48550/arXiv.2510.21654}, url = {https://arxiv.org/abs/2510.21654}, keywords = {Human pose estimation, IMU, UWB, multi-person tracking, global translation}, month = oct }
More images
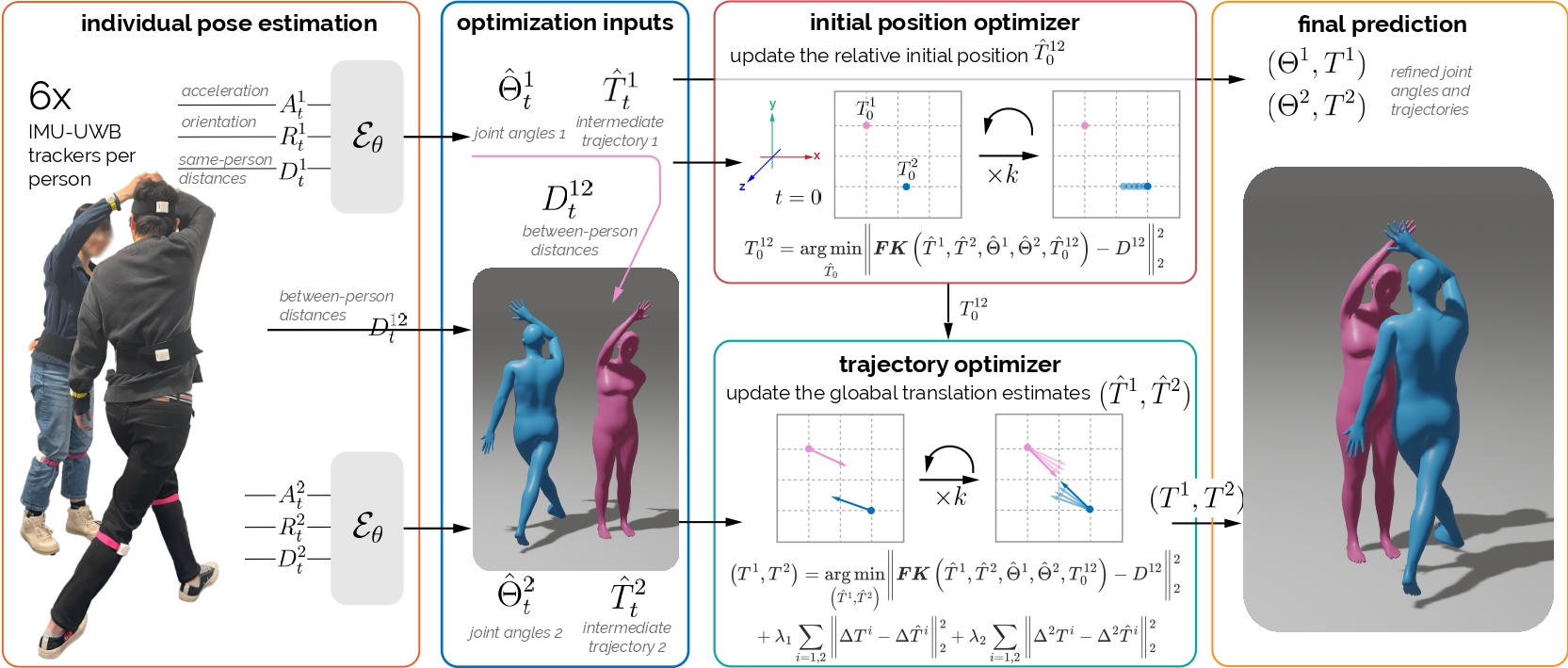
Figure 2: Overview of Group Inertial Poser (GIP). Our pipeline consists of three key steps. It begins with individual pose estimation using an SSM-based model to generate a full-body SMPL pose and translations. The optimization steps then refine these estimates by minimizing the discrepancy between predicted and actual between-sensor distances. First, GIP optimizes the initial relative positions; second, it fine-tunes the translations for both users.
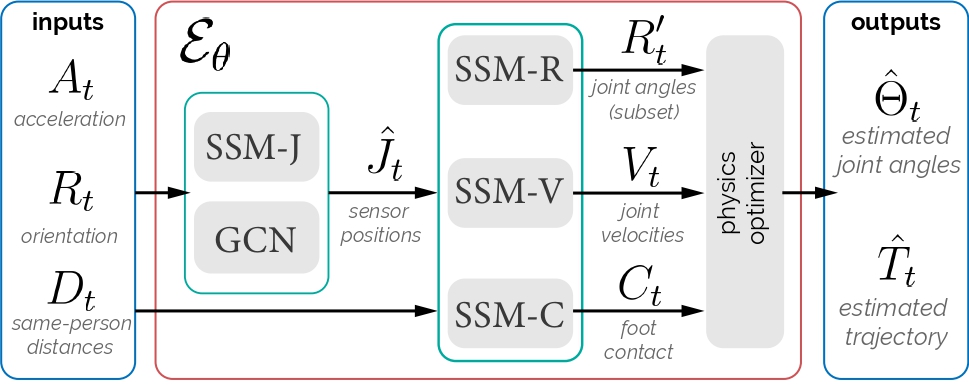
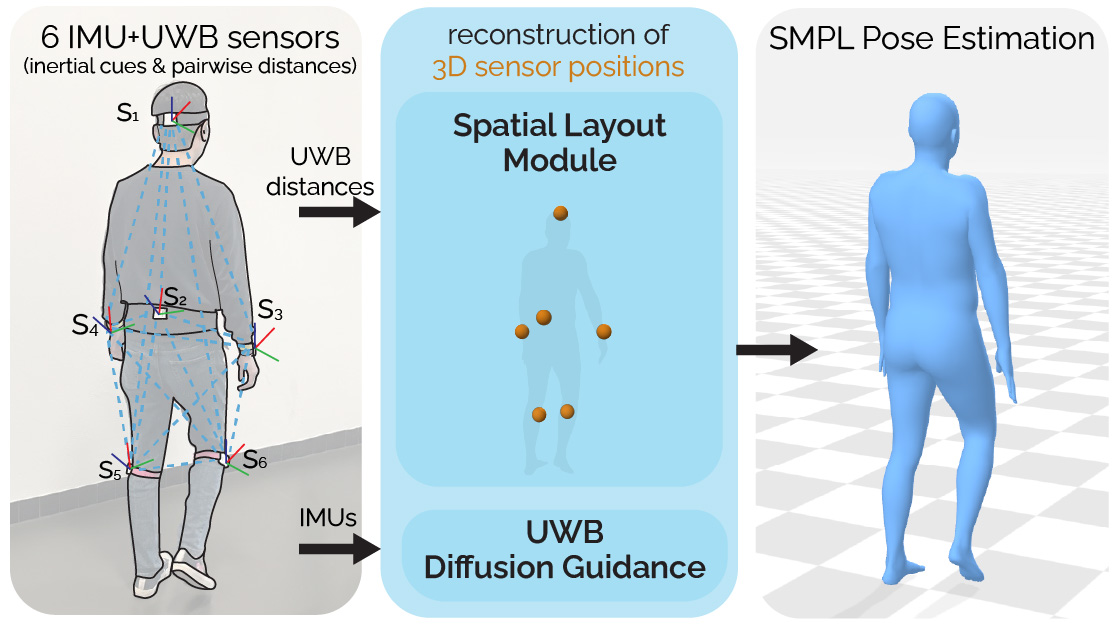
Figure 3: Our SSM-based model takes the global acceleration, rotation, and between-sensor distances to estimate the pose and translation via SMPL.
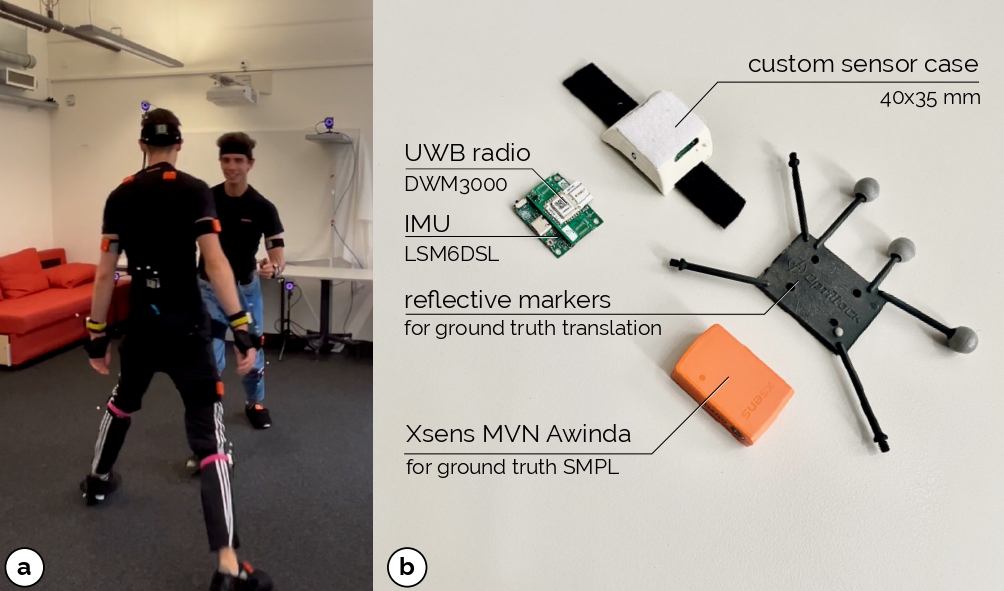
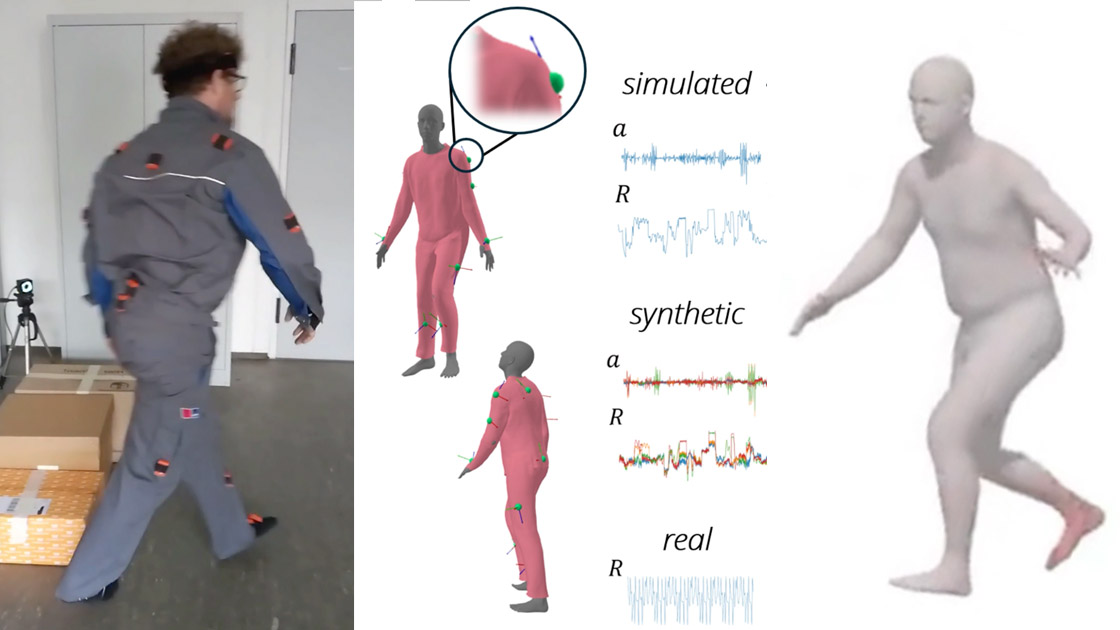
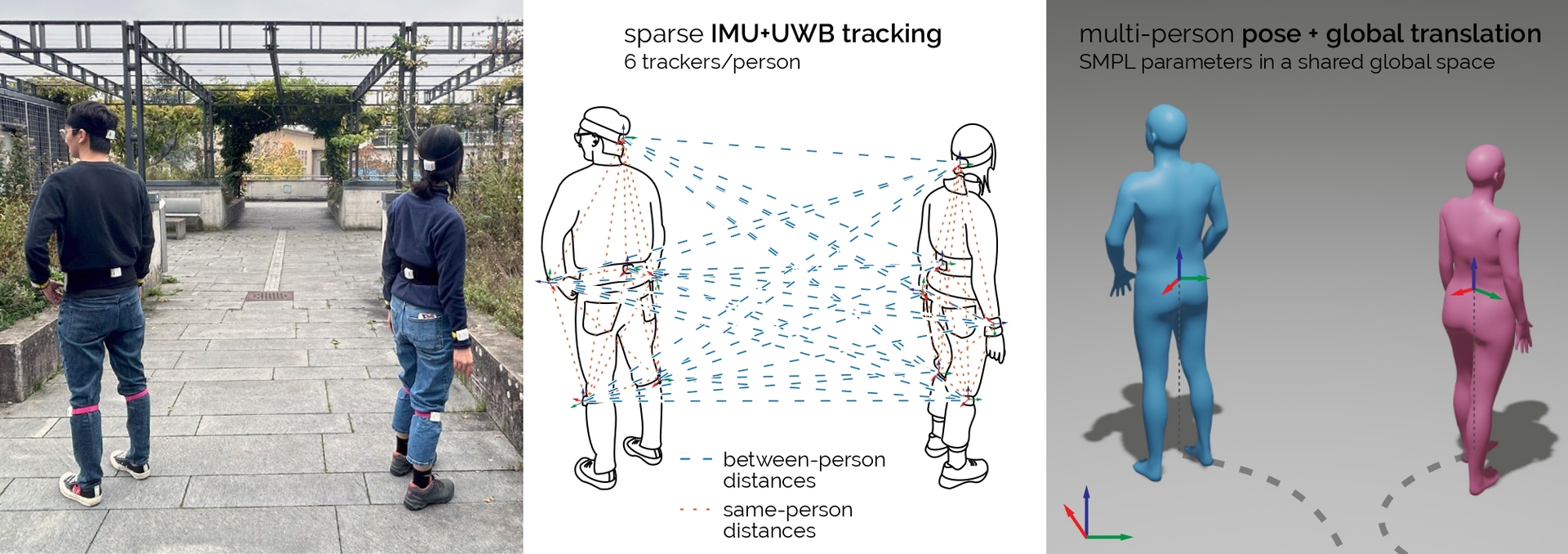
Figure 4. (a) Our dataset includes pairs of participants equipped with (b) various motion capture sensors. These sensors capture acceleration, orientation, and distance data, along with groundtruth SMPL pose parameters and translations for each participant.

Table 1: Results for training on AMASS and evaluation on the InterHuman dataset. When directly comparing with PIP and UIP, we assume the initial position is known for all methods (upper table), as PIP and UIP cannot predict the initial relative translations. We also report results when GIP is not initialized with ground truth but using our initial position optimizer, which only affects the translation errors and shows comparable performance to the ground truth initialization. The best results are in bold.
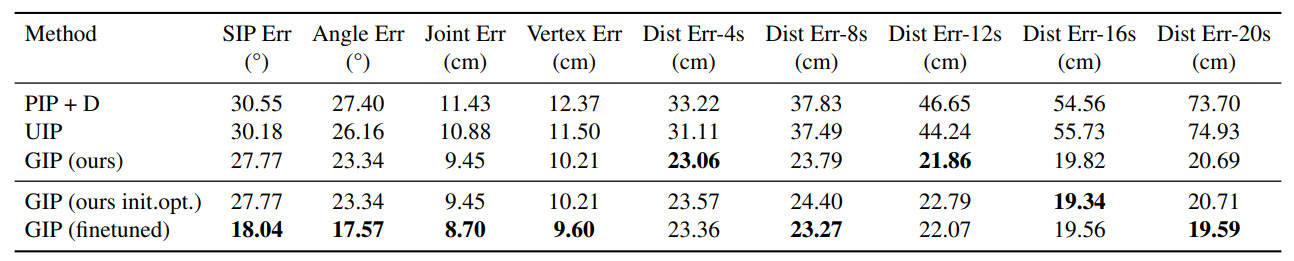
Table 2. Results for training on AMASS data and evaluation on the real-world GIP-DB dataset. When directly comparing with PIP and UIP, we assume the initial position is known for all methods, as PIP and UIP cannot predict the initial translation.

Figure 6. Visual comparison of GIP and UIP. GIP effectively corrects trajectory errors and preserves inter-personal interaction dynamics.